
Try Agora for Free
Sign up and start building! You don’t pay until you scale.

David Ubong Ekanem is a creative software engineer who enjoys building applications that explore new technologies and the link between learning and writing.
Interested in writing an Agora tutorial blog? Send us your topic today!
Communication is an essential part of our daily lives. With the proliferation of mobile technology, voice chat applications enable interconnectivity. Keeping track of what was said in the meeting can be challenging during video meetings.
Come with me as we build a service that’s useful for taking notes by students or businesses. We will build a React Native application that supports speech-to-text transcription. We’ll go over the structure, setup, and execution of the app before diving into how it works.
We’ll be using the Agora RTC SDK for React Native for the example below. I’m using v4.1.0 at the time of writing.
Go to https://console.agora.io/ to create an account and log in to the dashboard. You can follow this guide for reference: https://www.agora.io/en/blog/how-to-get-started-with-agora.
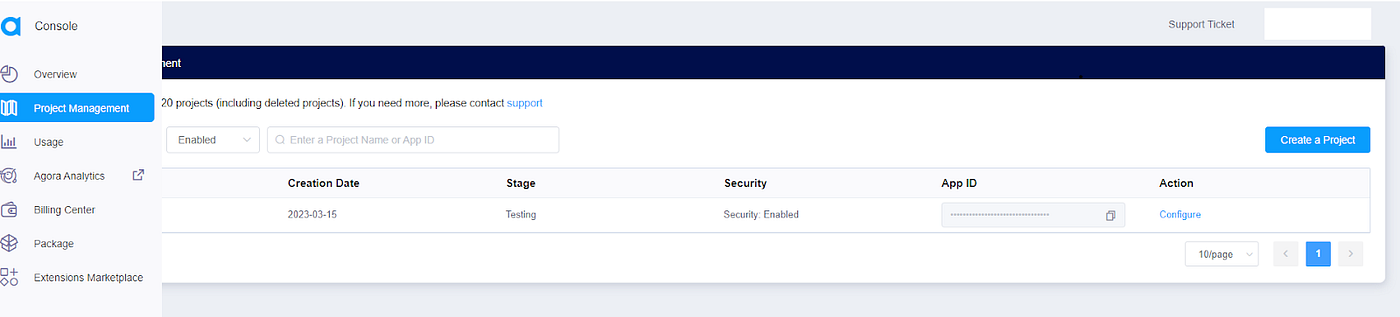
Click the sidebar then click the Project Management tab, under Project Management. Click the Create Project button to create a new project.
Once the project is created, retrieve the App ID. Select an App ID with a token, and obtain a temporary token for the project. On the edit page, click the link to generate a temporary token. The temporary token is used for authorizing requests while developing the application.
Note: Token authentication is recommended for all RTE apps running in production environments. For more information about token-based authentication on the Agora platform, see this guide: https://docs.agora.io/en/Video/token?platform=All%20Platforms
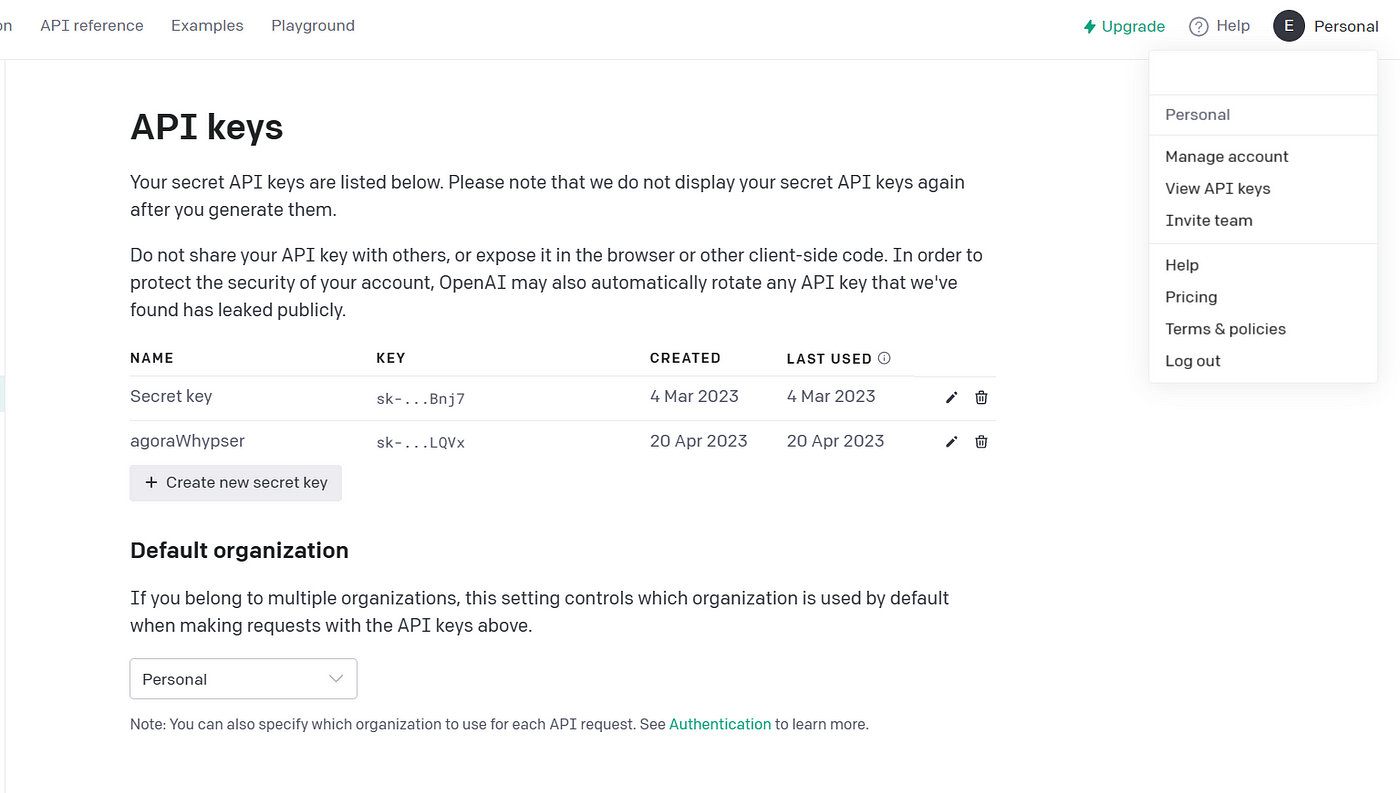
Go to https://platform.openai.com/ to create an account, and log in to the dashboard. Click the user section tab and select View API keys. Retrieve the API key, or create a new one specifically for this project.
The LTS version of Node.js and NPM need to be installed on your system.
That’s it. You should be able to join or leave a call. The app uses the agoraReactNativeStream as the channel name.
We’re exporting a component that accepts the transcribed text and interimTranscribedText and displays the TranscribedText. This is used for displaying the transcribed text from our video call.
The App.tsx file contains the core logic of our video call.
We start by writing the import statements. Next, we have some constants for our App ID, token, open-AI key, and channel name. The other constants (sample rate, number of channels, and samples per call) specify how we want to store our audio file.
We define a functional component in which the agoraEngineClass variable stores the IRtcEngine class. This class provides methods that we can invoke in our application to manage the video call. The useState hook stores the data of our transcribed text.
The setupVideoSDKEngine initializes the Agora engine on app start. The application requests needed permissions, and if they are granted, the Agora engine initializes. We register the audioFrameObserver to be able to access onPlayAudioFrame methods if needed.
The join function is particularly useful as it enables us to join our desired channel. If transcribedText is available in the state, we clear it before joining the channel. We trigger the startAudioRecording method. We pass in the desired filePath for storing our audio.
We rely on the React Native File System to access the native file system of our React Native application. Encoding is set to false, and the constant SAMPLE_RATE represents the sample rate. Set the fileRecordingType to AudioFileRecordingMixed. We are set to record the mixed audio of the local and all remote users.
The leave function enables the user to exit the channel and stops the audio recording. We unregister the earlier register audioFrameObserver. The application triggers the startTranscribe function once the audioRecording ends.
In the startTranscribe function, the recordingPath and fileName make up the filePath. This filePath shows the way to the audioData. The whisperAPI receives the audioData, and we receive the transcribed text.
We define the render function for displaying the buttons for joining or leaving a call. The render function also displays our transcribed text.
Our finished application.
That’s how easy it is to build a transcription application inside a video call application. You can refer to the Agora React Native API Reference to see methods that can help us quickly add additional features to our application.
If you’re deploying your app to production, you can read more about how to use tokens in this blog post.
I invite you to join the Agora Developer Slack Community. Feel free to ask any React Native questions in the #react-native-help-me channel.






