



在 Meta 中执行精确时间协议(PTP)可以将产品和服务系统的时间精确到到纳秒。PTP 的前身——网络时间协议(NTP)可以精确到毫秒。随着新一代计算平台、元宇宙和人工智能等更先进系统的构建,我们要保证服务器的时间尽可能精确。无论是在通信、生产力还是娱乐、隐私和安全等各个方面,PTP 都可以增强 Meta 的技术和程序,为全球用户提供服务。
因为必须重新考量如何让计时硬件和软件同时在服务器和数据中心运作,我们花费了多年时间最终构建了 PTP。
本文将深入探究 PTP 迁移和我们的创新。
目录
• PTP 案例
• PTP 架构
- PTP 机架
- PTP 网络
- PTP 客户端
• 如何监控 PTP 架构
PTP 案例
在深入研究 PTP 架构之前,我们先来探讨一个极其精确计时的简单用例。
假设一个客户写了数据,并且想立即读取该数据,那么在大型分布式系统中,写和读很有可能会落在不同的后端节点上。
如果读到的是还未更新的远程副本,用户就有可能看不到自己的写的内容:
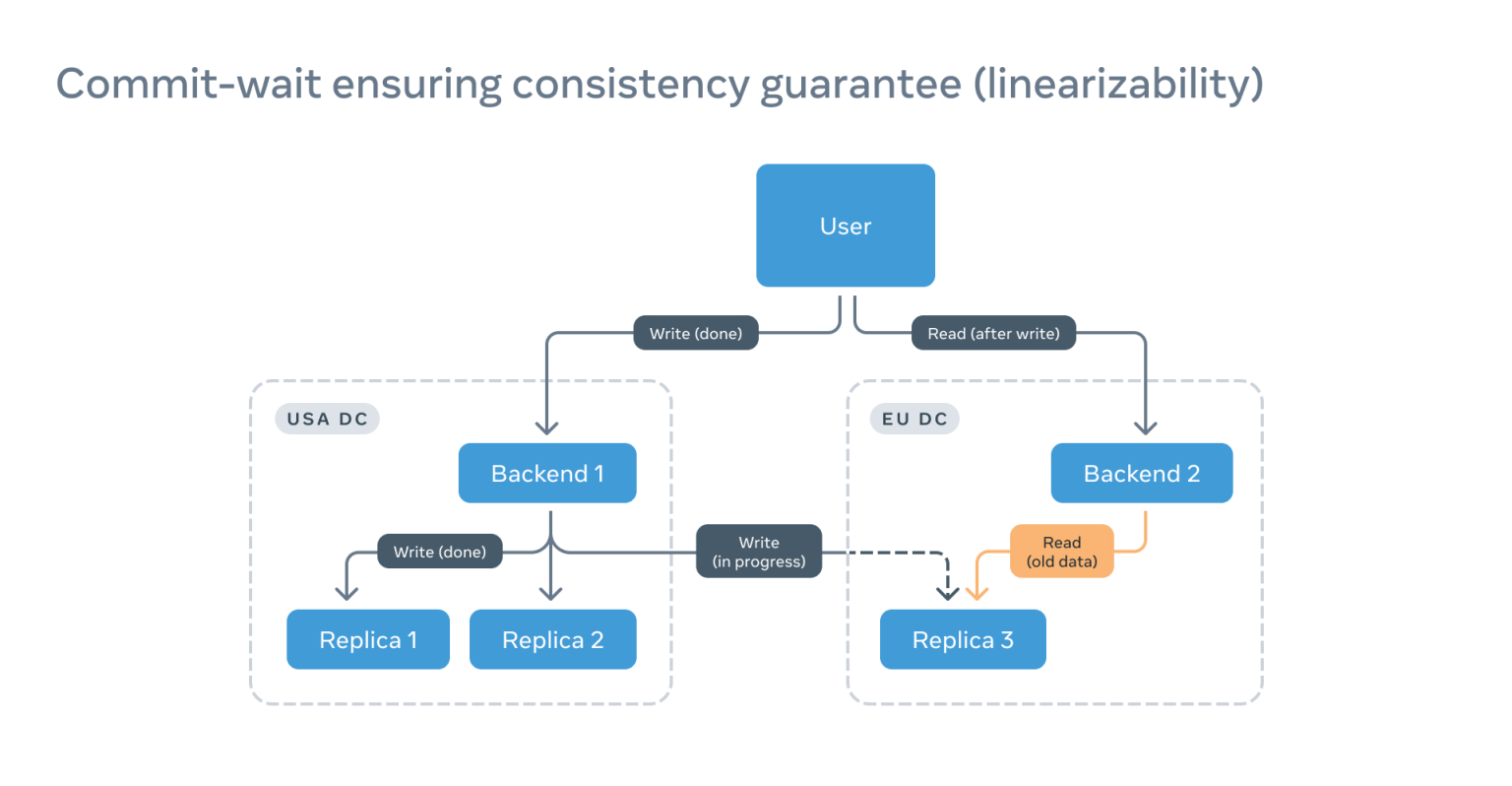 读取返回的过期信息的示意图
读取返回的过期信息的示意图
这种情况不仅很棘手,而且违反了线性化一致性保证。线性一致性保证可以让分布式系统的交互方式与单一服务器的交互方式相同。
解决这个问题的典型方法是向不同副本发出多次读取,使用出现次数最多的读取。但这样不仅浪费资源,还会因网络往返延迟过长,导致读取延迟。
如果在后端和副本上添加精确的时间戳,我们就只需等副本赶上读取时间戳:
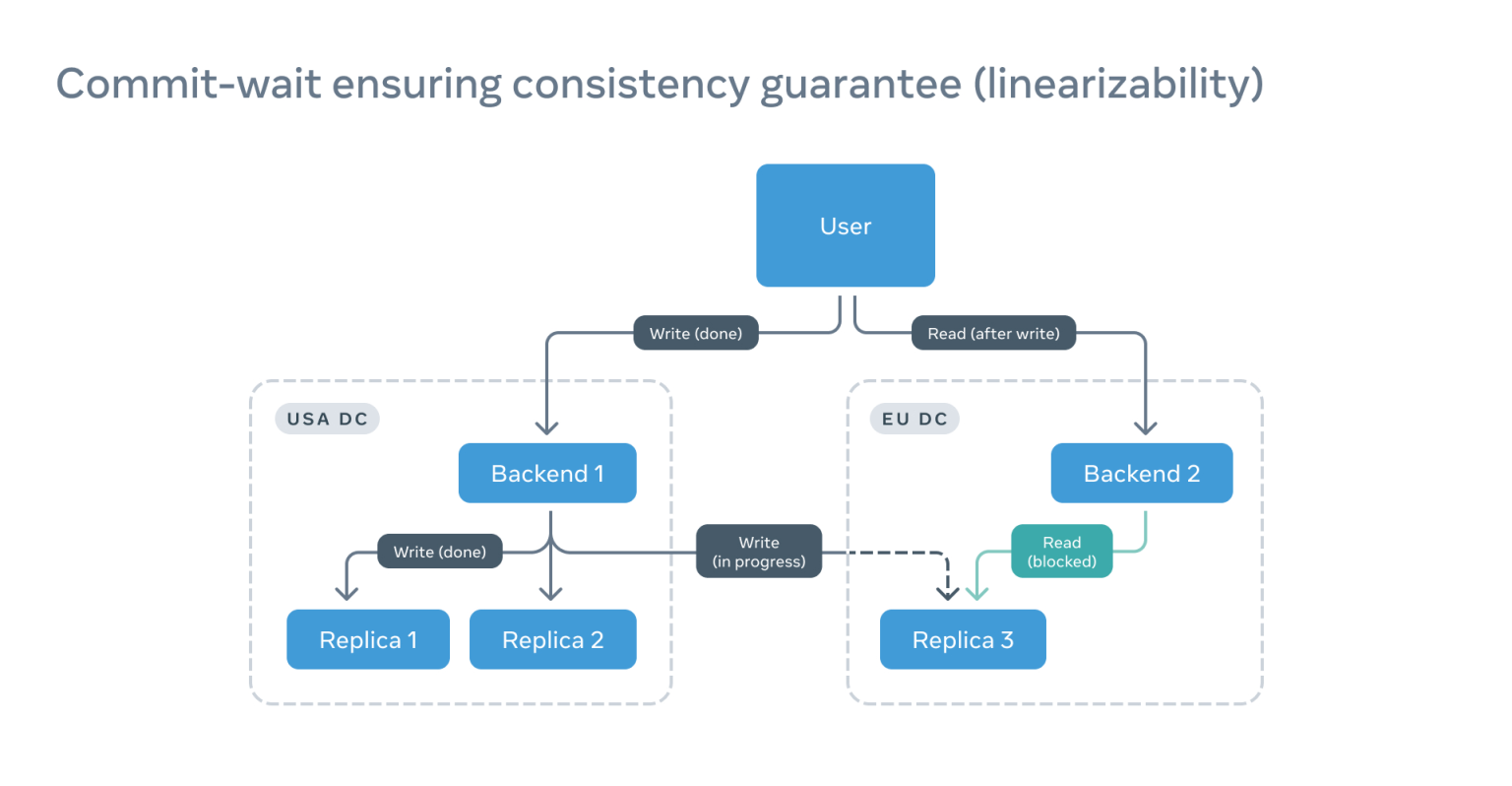
这样不仅能加快读取速度,还能节省大量算力。
运行此设计的一个重要条件是:所有时钟都要同步或是时钟和时间源之间的偏移量是确定的,但是偏移量会随着不断修正、偏差或温度变化而改变。因此,我们使用了不确定窗口(WOU)概念,概率最大的窗口就是偏移出现的位置。在本例中,如果没有在读取时间戳上添加 WOU,读取会被阻止。
可能会有用户认为不需要 PTP,只用 NTP 就够用了,其实我们之前也这么认为,我们通过实验比较了最先进的 NTP 和早期的 PTP,发现两者在性能方面有大约 100 倍的差异:
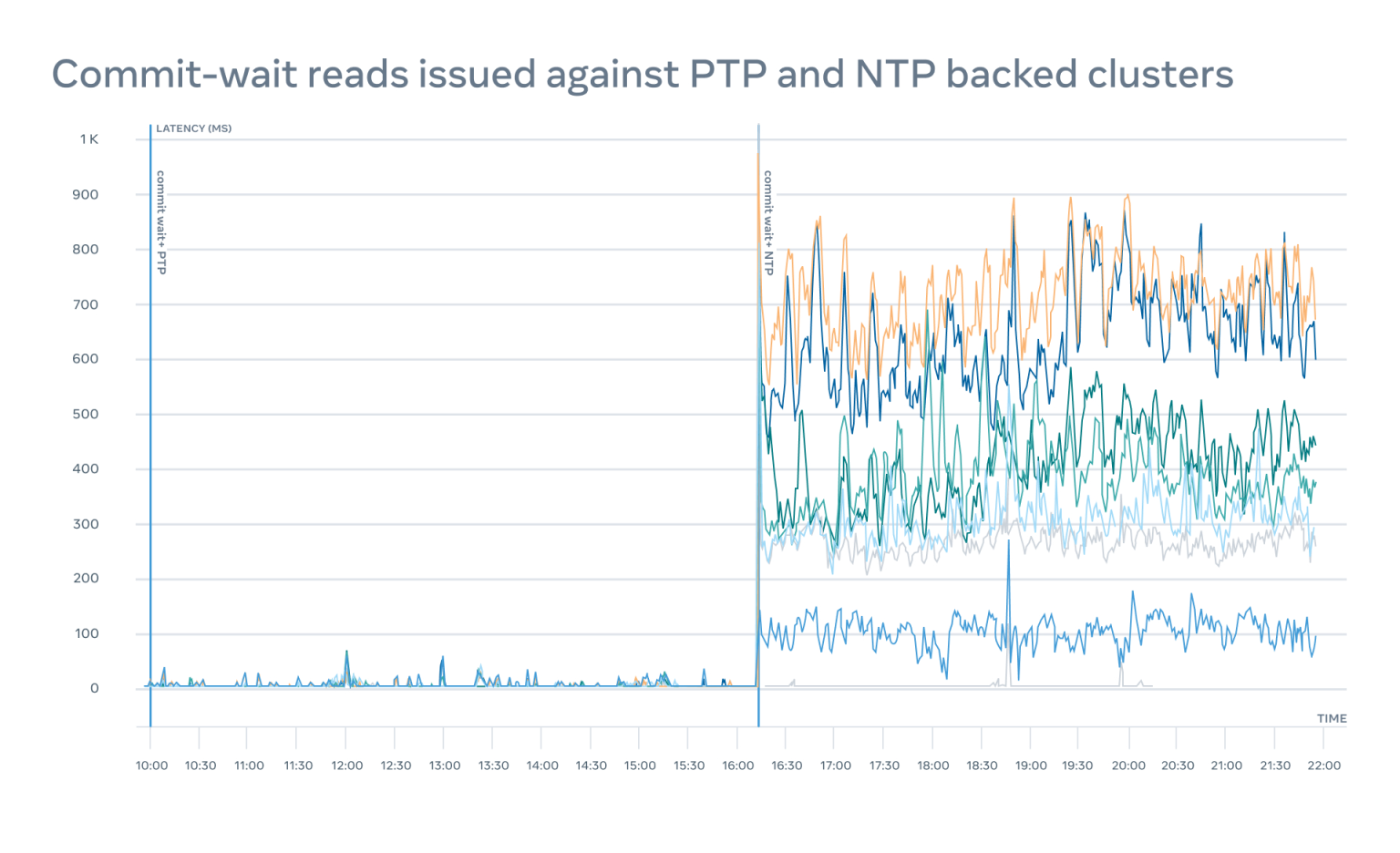
还有其他几个用例,包括事件追踪、缓存失效、隐私泄露检测的改进、元宇宙中的延迟补偿以及人工智能中的同时执行,很多都会大幅降低在硬件容量方面的要求,这些都是我们接下来的研究重点。
现在,我们来看看如何在 Meta 上部署 PTP。
PTP 架构
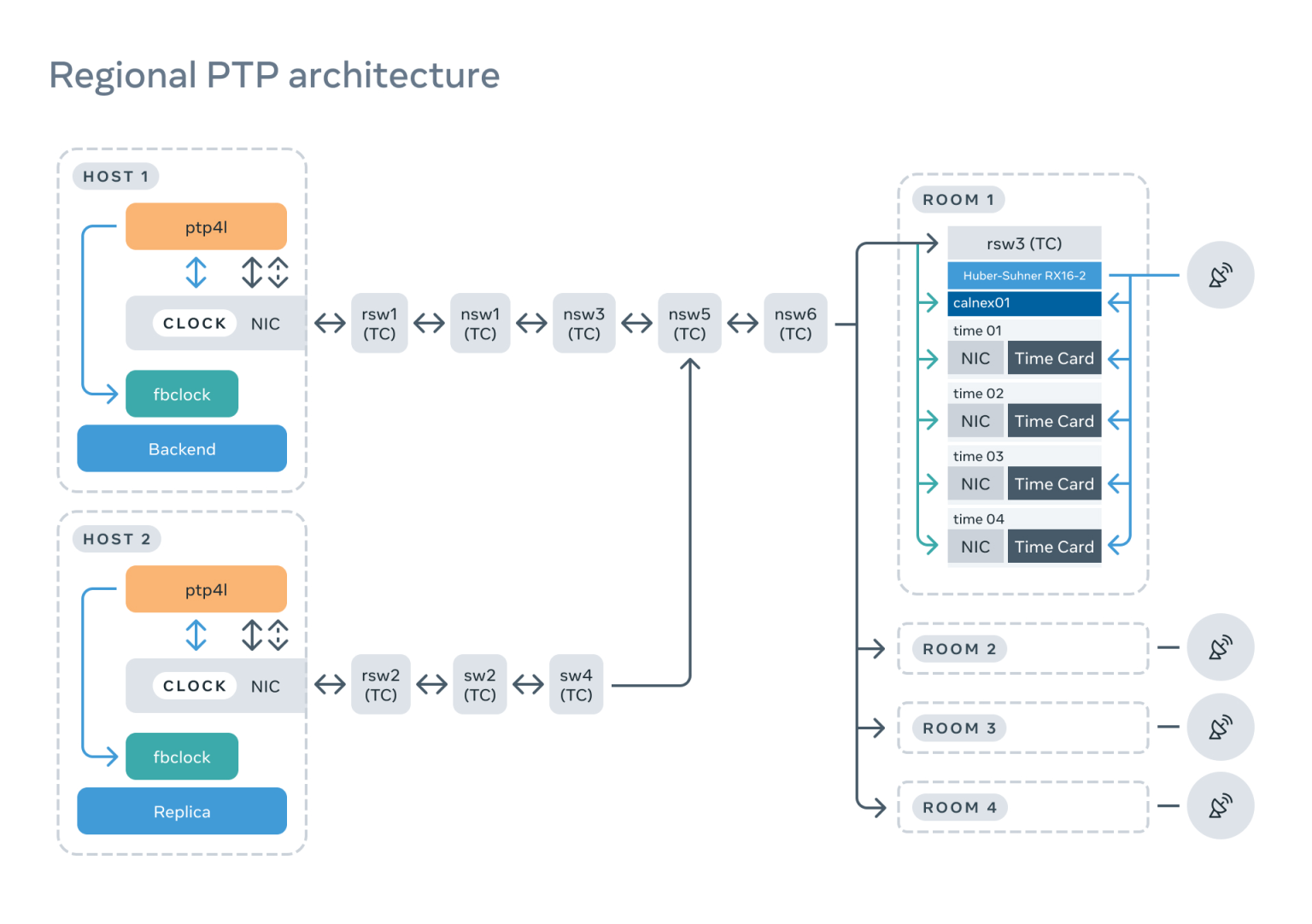
经过几次可靠性和操作性审查之后,我们把设计分成三个主要部分:PTP 机架、网络和客户端。
我们会在下文一一分析。
PTP 机架
PTP 机架包含了为客户提供时间服务的硬件和软件;机架由多个关键部件组成,每个部件都经过了精心挑选和测试。
天线
GNSS 天线容易被忽视,但它是时间的来源。
我们在努力争取达到纳秒级的精度。如果 GNSS 接收器不能准确地确定位置,就无法计算时间。我们必须多考虑信噪比(SNR)。质量较低的天线以及空中障碍物都会导致很高的三维位置标准差错误。为获得最精确的时间,GNSS 接收机应进入时间模式,这通常要求三维误差小于 10 米。
必须确保环境开阔且安装一个固定天线。这样还能欣赏美丽的景色:

在测试不同的天线解决方案时,一种相对较新的 GNSS-over-fiber 技术引起了我们的注意。它几乎完美避开了所有缺点——它不导电,因为它是由激光通过光纤供电的,而且它的信号可以在没有放大器的情况下传播几公里。
在建筑物内,它可以使用已有的结构化光纤和 LC 配线架,能大幅简化信号的分配。此外,光纤的信号延迟是很明确的,大约为每米 4.9 纳秒。剩下的就是由直接的射频到激光调制和光分路器引入的延迟,每盒约为 45 纳秒。

通过测试,我们确认端到端的天线延迟是确定的(通常约为几百纳秒),并且很容易地在时间设备端进行补偿。
计时设备
计时设备是计时基础设施的核心。从数据中心的基础设施的角度看,计时设备直接决定时间。我们在2021 年发表了一篇文章,解释了为什么我们要开发一个新的计时设备,为什么当前所有的解决方案都不能满足我们的需求。
但当时使用的是 NTP。现在,PTP 带来了更高的要求和更严格的限制。最重要的是,我们承诺在不影响精确性的情况下,让每台设备支持多达 100 万个客户。为了实现这个目标,我们仔细审查了计时设备的许多传统组件,并严格测试了其可靠性和多样性。
时间卡

为保证我们的基础设施不出现关键故障或遭受恶意攻击,我们决定从时间卡开始实现多样化。上次,我们谈了很多时间卡的设计和基于 FPGA 的解决方案的优势。我们正在与 Orolia、 Meinberg、Nvidia、Intel、Broadcom 和 ADVA 等供应商在开放计算项目(OCP)下合作,他们都执行自己的时间卡,符合 OCP 规范。
摆动器
时间卡是一个关键部件,需要特殊的配置和监控。因此,我们与 Orolia 合作,为不同类型的时间卡开发了一个名为 oscillatord 的调控软件,该软件已经成为默认工具:
- GNSS 接收机配置:设置默认配置,并调整天线延迟补偿等特殊参数。它还可以禁用任何数量的 GNSS 星座,以模拟保持场景。
- GNSS 接收机监测:报告卫星数量、GNSS 质量、不同星座的可用性、天线状态、闰秒等。
- 原子钟配置:不同的原子钟需要不同的配置和事件顺序。例如,SA53 TAU 配置可以实现快速调控,而 mRO-50 支持温度频率关系表。
- 原子钟监测:必须对激光器温度和锁定等参数进行全面监测,当数值超出运行范围时必须做出快速决定。
从摆动器中导出的数据非常有效,我们可以决定计时设备应该接收流量还是排出流量。
网卡
我们的最终目标是在分组网络上使用 PTP 等协议。如果说时间卡是计时设备的核心,那么网卡就是计时设备的外表。每个时间敏感 PTP 数据包都会被网卡打上硬件时间戳,所以网卡的 PTP 硬件时钟(PHC)必须被准确控制。
如果我们简单地将时钟值从时间卡复制到网卡上,使用 phc2sys 或类似的工具,精确度将远远不够。我们的实验表明,在通过 PCIe、CPU、NUMA 等时很容易损失 1-2 微秒。随着新兴的精密时间测量(PTM)技术的发展,PCIe 总线的同步性能会得到极大改善,因为具有这种能力的各种外设正得到逐步开发。
对于我们的应用来说,由于我们使用得是具有 PPS 输入功能的网卡,我们采用了 ts2phc,它首先复制时钟值,然后根据每秒脉冲(PPS)信号来对齐时钟边缘。这需要在时间卡的 PPS 输出和网卡的 PPS 输入之间增加一条电缆,如下图所示:

我们不断地监测偏移量,确保它在时间卡和网卡之间不会超出 ±50 纳秒的窗口:
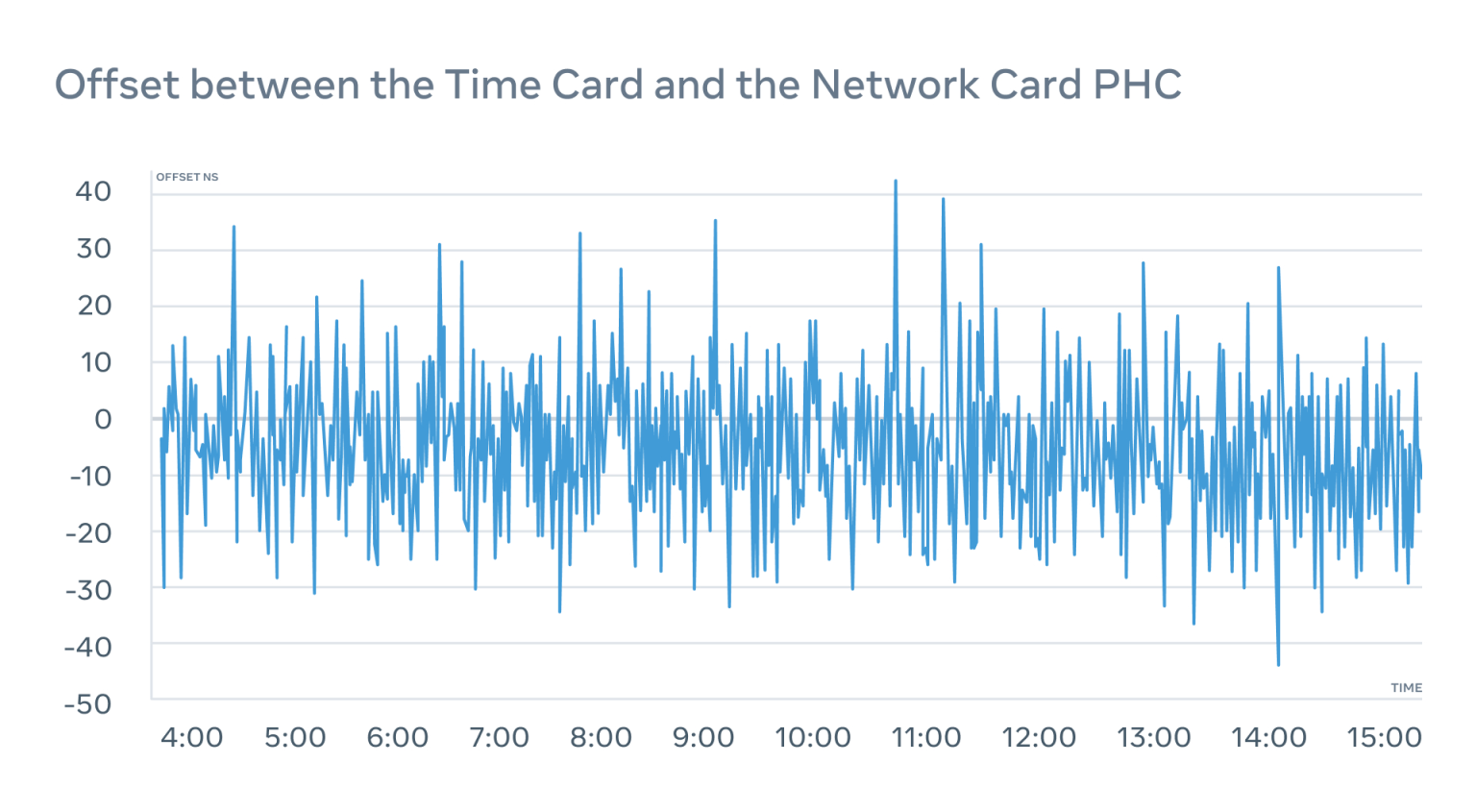
我们还监测了网卡的 PPS-out 接口,作为故障保护措施,确保我们能知道网卡上的 PHC 发生了什么。
ptp4u
在评估不同 PTP 服务器的执行时,我们遇到了开源和封闭专有的解决方案的扩展性问题,包括我们评估的 FPGA 加速的 PTP 服务器。最好的情况是我们在每个服务器上获得大约 5 万个客户,我们不得不部署许多机架的这些设备。
PTP 的诀窍是使用硬件时间戳,服务器的执行不必是高度优化的 C 程序,甚至不一定是 FPGA 加速器。
我们在 Go 中实现了一个可扩展的 PTPv2 单播 PTP 服务器,我们将其命名为 tp4u,并在 GitHub 上进行了开源。通过一些小的优化,我们能够每个设备上支持超过 100 万个并发客户端,这一点已被一个通过 IEEE 1588v2 认证的设备独立验证。
这是通过在 Go 中简单地使用通道来实现的,它能让我们在多个强大的工作者之间传递订阅信息。
因为 ptp4u 是作为进程在 Linux 机器上运行,我们能自动且免费地得到所有的好处,如 IPv6 支持、防火墙等。
c4u
ptp4u 服务器有许多配置选项,可以将动态变化的参数,比如 PTP 时钟精度、 PTP 时钟类别和 UTC 偏移(目前设置为 37 秒,我们期待这成为一个常数)传递给客户端。
为了经常生成这些参数,我们执行了一个单独的服务—— c4u,它能不断监测几个信息源,并为 tp4u 编译活动配置:
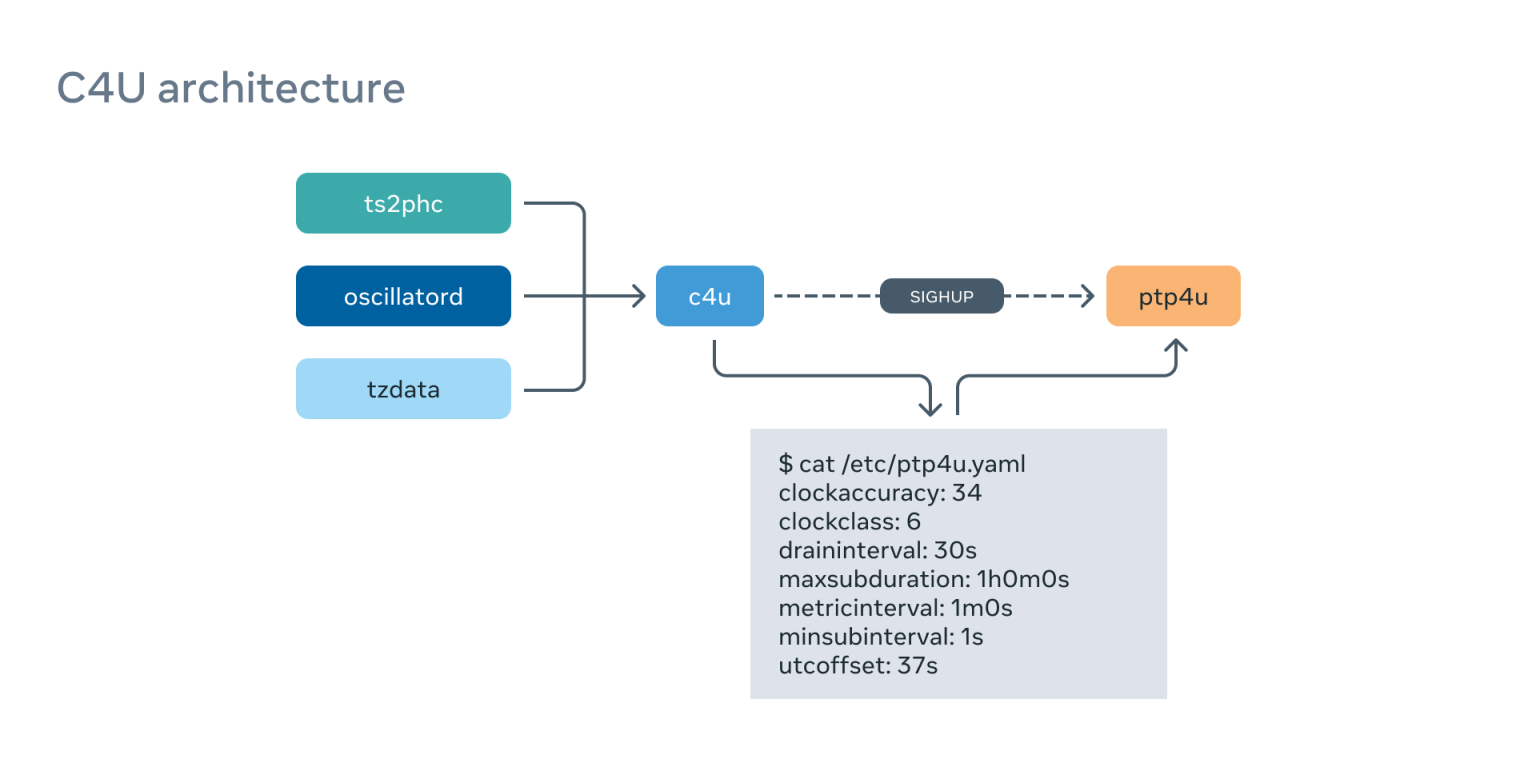
它可以让我们在环境发生变化时具有灵活性和反应性。例如,如果我们在一个时间设备上失去了 GNSS 信号,就会把 ClockClass 切换到 HOLDOVER,客户将立即从它那里迁移。它还从许多不同的来源计算 ClockAccuracy,如 ts2phc 同步质量、原子钟状态等。
我们根据 tzdata 包的内容来计算 UTC 的偏移值,因为我们把国际原子时间(TAI)传输给客户。
Calnex 哨兵
我们想确保时间设备能不断被完善的认证监测设备独立评估。目前,我们已经与 Calnex 在 NTP space 取得了很大的进展,我们可以将类似的方法应用于 PTP。
我们与 Calnex 合作,将他们的现场设备重新用于数据中心,这涉及到改变物理外形尺寸和增加对 IPv6 等功能的支持。

我们将 Time Appliance NIC PPS-out 连接到 Calnex Sentinel,就能以纳秒级的精度监测网卡的 PHC。
我们将在下文“如何监控 PTP 架构”中详细探讨监控问题。
PTP 网络
PTP 协议
PTP 协议支持使用单播和组播模式来传输 PTP 信息。大型数据中心的部署更偏好单播,因为单播能明显简化网络设计和软件要求。
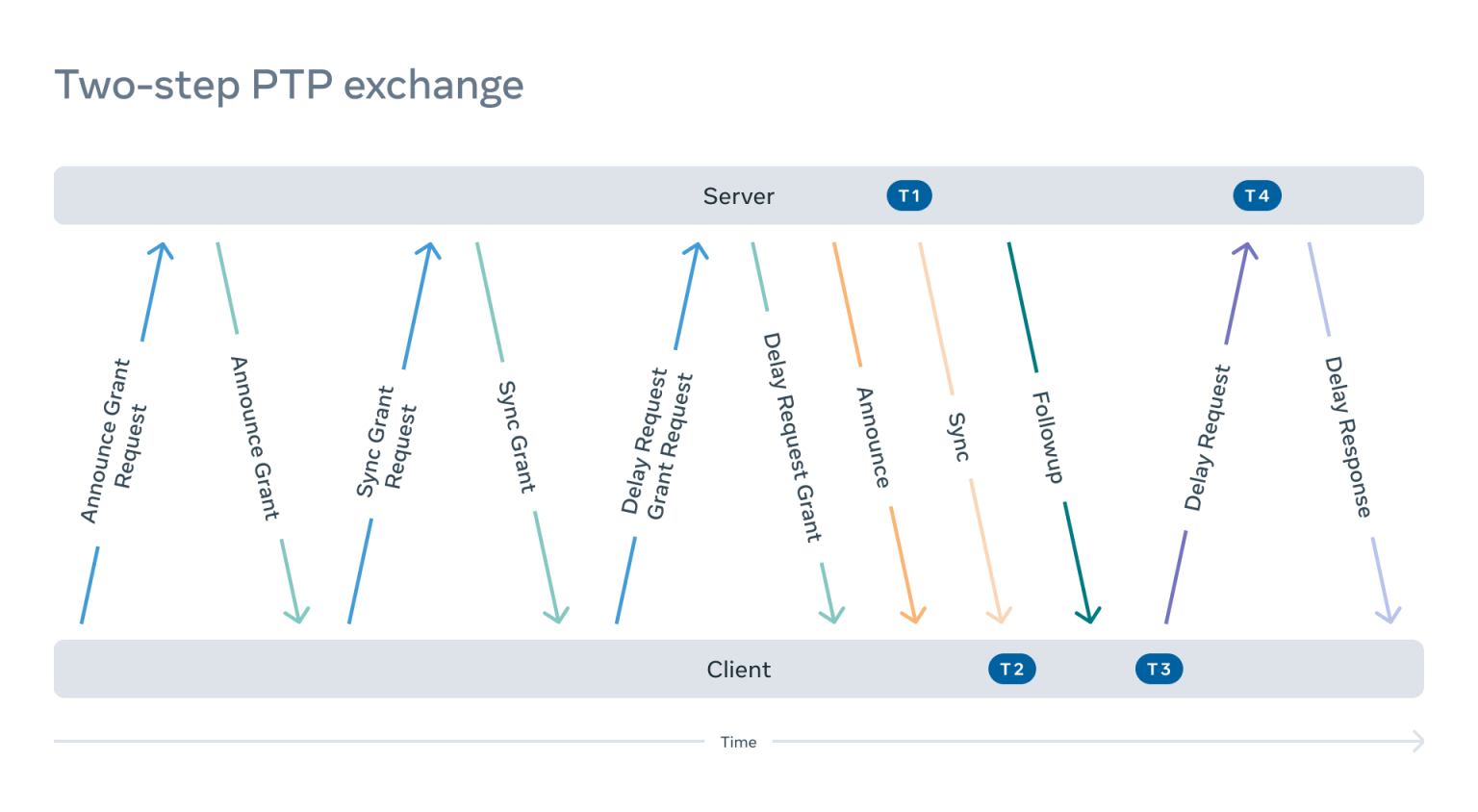
我们来看一个典型的 PTP 单播流:
一个客户开始协商(请求单播传输)。因此,它必须发送:
- 一个同步授权请求(“嘿,服务器,请在接下来的 M 分钟内每秒向我发送 N 条同步和跟进信息,并提供实时时间”)。
- 一个公告授予请求(“嘿,服务器,请每秒向我发送 X 条公告信息,说明你在未来 Y 分钟的状态”)。
- 一个延迟响应授权请求(“嘿,服务器,我将向你发送延迟请求,请在接下来的 Z 分钟内用延迟响应数据包进行响应”)。
2. 服务器需要授予这些请求并发送授予响应。
3. 接下来,服务器需要开始执行订阅并发送 PTP 信息。
- 所有的订阅都是相互独立的。
- 服务器要遵守发送间隔,并在过期时终止订阅(PTP 最初只有组播,在这个设计中可以清楚地看到组播的起源)。
- 在两步配置中,当服务器发送同步消息时,它必须读取 TX 硬件的时间戳,并发送包含该时间戳的后续消息。
4. 客户端将在商定的时间间隔内发送延迟请求,以确定路径延迟。服务器需要读取 RX 硬件的时间戳并将其返回给客户端。
5. 客户端需要定期刷新拨款,这个过程会重复进行。
计划如下图:
透明时钟
我们最初考虑在我们的设计中利用边界时钟。然而,边界时钟有下列缺点:
- 需要网络设备或一些特殊的服务器来充当边界时钟。
- 边界时钟作为一个时间服务器,对短期稳定性和保持性能有更高的要求。
- 由于信息必须通过边界时钟从时间服务器向下传递到客户端,我们不得不为此提供特殊支持。
为了避免不必要的麻烦,我们决定全部使用 PTP 透明时钟。
透明时钟(TC)让客户能够考虑到网络延迟的变化,确保对时钟偏移进行更精确的估计。客户端和时间服务器之间路径上的每个数据中心交换机通过更新数据包有效载荷中的一个字段——修正字段(CF),来报告每个 PTP 数据包在交换机上花费的时间。
PTP 客户(也被称为普通时钟,或 OC)使用四个时间戳(T1、T2、T3 和 T4)和两个校正域值(CFa 和 CFb)计算网络平均路径延迟和时钟偏移到时间服务器(祖师级时钟,或 GM),如下图所示:
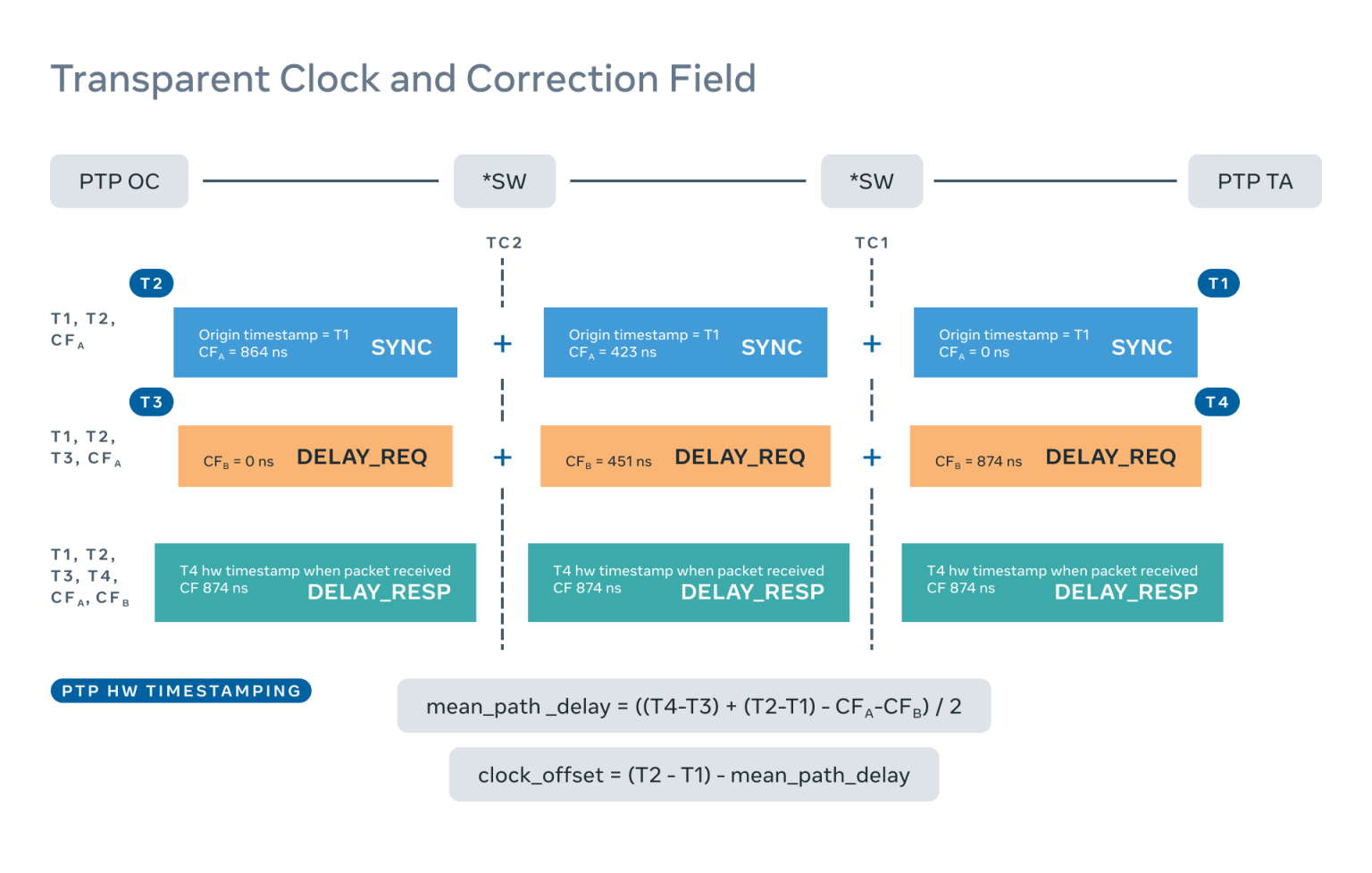
- T1 是时间服务器发送 SYNC 数据包时的硬件时间戳。
- T2 是 OC 收到 SYNC 数据包时的硬件时间戳。
- CFa 是在从时间服务器到客户端的路径中每个交换机(TC)记录的交换机延迟的总和(对于 SYNC 包)。
- T3 是客户端发送延迟请求的硬件时间戳。
- T4 是时间服务器收到延迟请求时的硬件时间戳。
- CFb 是在从客户端到时间服务器的路径上每个交换机记录的交换机延迟的总和(对于延迟请求包)。
要了解只禁用一个透明时钟对客户和服务器之间的影响,我们可以查看日志。

我们可以看到路径延迟爆炸,有时甚至成为负值,这通常不会发生在正常操作中。这对偏移量产生了巨大的影响,使其从 ±100 纳秒变为-400 微秒(大于 4000 倍的差异)。最糟糕的是,这个偏移量不准确,因为平均路径延迟的计算是不正确的。
根据我们的实验,具有大缓冲区的现代交换机可以将数据包延迟到几毫秒,这会导致数百微秒的路径延迟计算误差,推动偏移峰值的出现,并在图表上清晰可见:
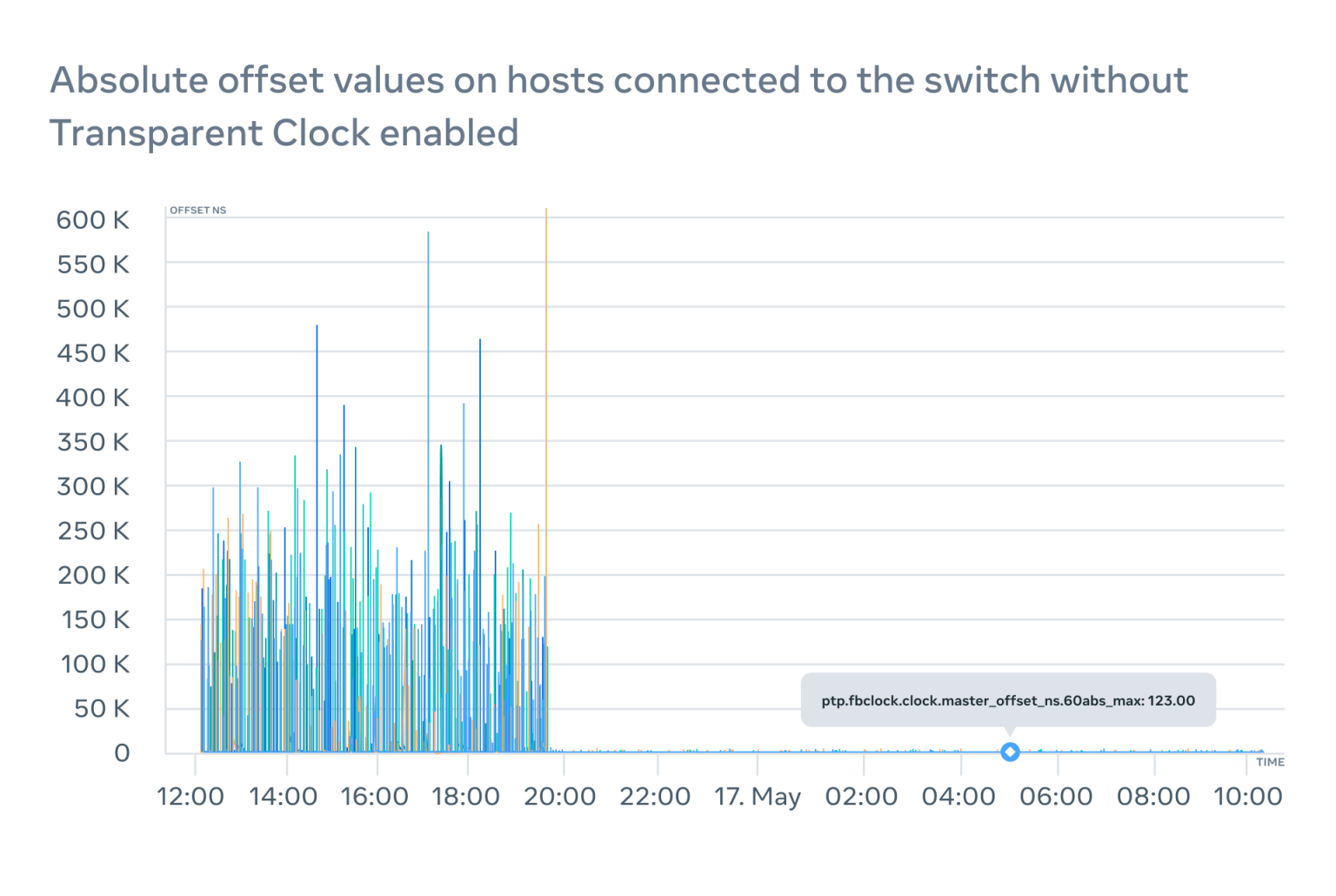
在没有 TC 的情况下,在数据中心运行 PTP 会导致不可预测和无法解释的往返时间不对称,而且,我们没有检测这一点的简单方法。500 微秒可能听起来不多,但在客户期望 WOU 为几微秒时,这样可能会违反 SLA。
PTP 客户端
时间戳
对传入的数据包进行时间标记是 Linux 内核几十年来支持的一个相对较老的功能。例如,软件(内核)时间戳已经被 NTP 守护程序使用了多年。重要的是要理解,时间戳默认不包括在数据包的有效载荷中,如有需要,必须由用户应用程序放在那里。
从用户空间读取 RX 时间戳是一个相对简单的操作。当数据包到达时,网卡(或内核)将对这一事件进行时间标记,并将时间标记包含在套接字控制信息中,通过调用设置了 MSG_ERRQUEUE 标志的 recvmsg syscall,很容易得到数据包。

对于 TX 硬件时间戳来说,情况就比较复杂了。当 sendto syscall 被执行时,不会导致数据包立即离开,也不会导致 TX 时间戳的产生。在这种情况下, 用户必须轮询套接字,直到时间戳被内核准确定位。通常我们必须等待几毫秒,这必然会限制发送速度。
硬件时间戳是 PTP 如此精确的诀窍所在。大多数现代网卡已经有硬件时间戳的支持,网卡驱动程序会填充相应的部分。
通过运行 ethtool 命令,可以非常容易地验证支持情况。
$ ethtool -T eth0
Time stamping parameters for eth0:
Capabilities:
hardware-transmit
hardware-receive
hardware-raw-clock
PTP Hardware Clock: 0
Hardware Transmit Timestamp Modes:
off
on
Hardware Receive Filter Modes:
none
All我们仍然可以使用有软件(内核)时间戳的 PTP,但其质量、精度和准确性无法保证。
我们也评估了这种可能性,甚至考虑在硬件时间戳不可用的情况下,在内核中实施改变,用软件来“伪造”硬件时间戳。然而,如果主机非常繁忙,我们观察到软件时间戳的精度跃升到数百微秒,我们就不得不放弃这个想法。
ptp4l
ptp4l 是一个开源软件,能够作为 PTP 客户端和 PTP 服务器。虽然由于性能问题,我们必须执行自己的 PTP 服务器解决方案,但我们决定坚持使用 tp4l 作为客户端的使用案例。
初步测试表明,tp4l 可以提供较好的同步质量,并将本地网络中的 PHC 上的时间调整到几十纳秒。
但是,随着设置规模的扩大,一些问题开始出现。
边缘案例
在一个例子中,我们注意到偏移量中偶尔出现“尖峰”。经过深入研究,我们发现了这个广受欢迎的网卡的基本硬件限制。
- 网卡只有 128 个数据包的时间戳缓冲器。
- 网卡无法区分 PTP 数据包(需要硬件时间戳)和其他不需要的数据包。
这最终导致合法的时间戳被来自其他数据包的时间戳所取代。而且,网卡驱动程序过于聪明,在没有告诉任何人的情况下将软件时间戳放在套接字控制信息的硬件时间戳部分。
这是一个基本的硬件限制,影响很大且不可修复。
我们不得不执行一个偏移异常值过滤器,这改变了 PI 伺服的行为,使其成为有状态的。它会丢弃偶尔的异常值,并在微保持期间设置平均频率:
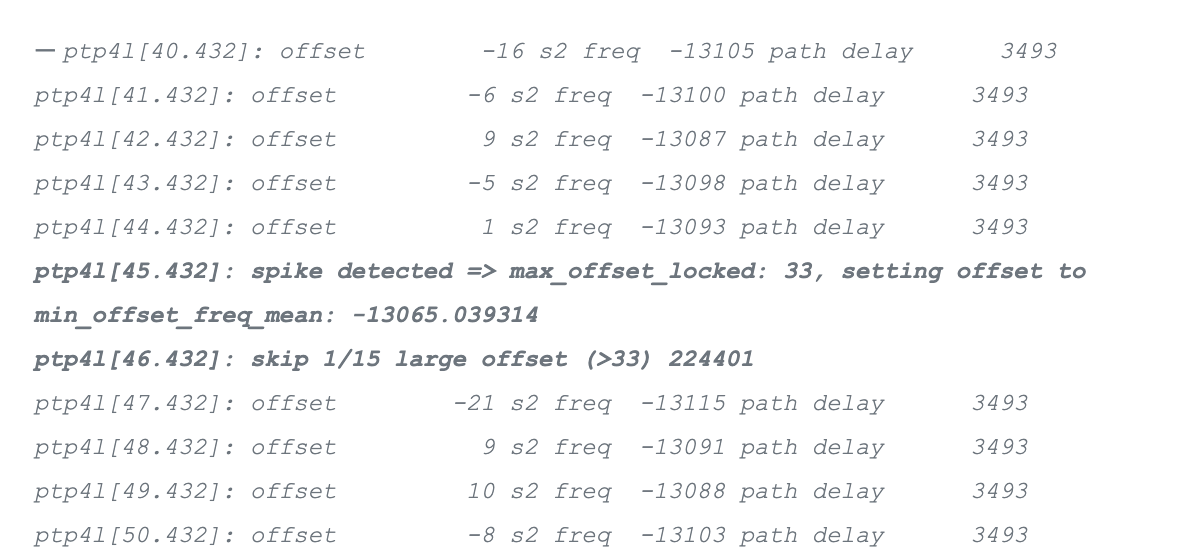
如果没有这个滤波器,tp4l 会把 PHC 的频率引导得非常高,这将导致几秒钟的振荡,而且从中获得的不确定性窗口的质量不好。
BMCA 的设计出现了另一个问题。这个算法的目的是在 ptp4l.conf 中有几个、可供选择的时间设备时选择最佳的时间设备。它通过比较时间服务器在 Announce 消息中提供的几个属性来实现。
- 优先级 1
- 钟表类
- 时钟精度
- 时钟偏差
- 优先级 2
- MAC 地址
当所有上述的属性都相同时,问题就会显现。BMCA 使用时间设备 MAC 地址作为分界线,这意味着在正常工作条件下,一个时间服务器将吸引所有的客户端流量。
为解决这个问题,我们引入了所谓的“分片”,将不同的 PTP 客户端分配给整个池中不同的时间设备子组。
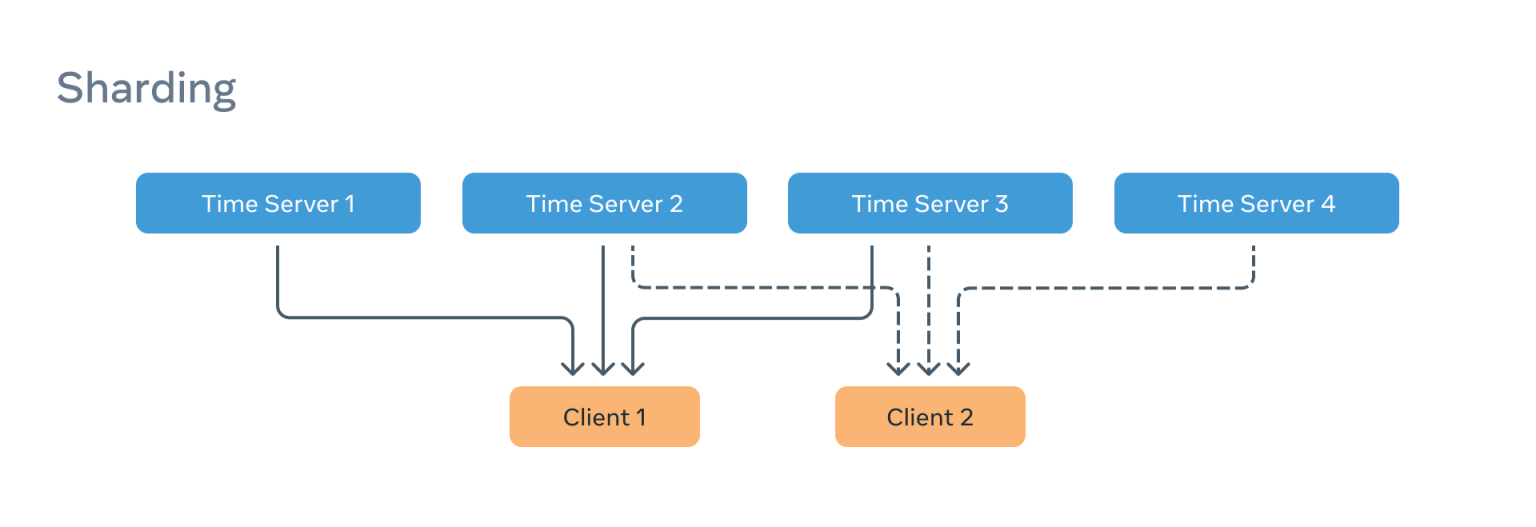
这只能解决每个分组中的一台服务器承担该分组的全部负载的一部分问题。解决方案是使客户能够表达偏好,因此我们在选择标准中引入了优先级 3,就在 MAC 地址平衡器的上方。 这意味着被配置为使用同一时间设备的客户可以选择不同的服务器。
Client 1:
[unicast_master_table]
UDPv6 time_server1 1
UDPv6 time_server2 2
UDPv6 time_server3 3
Client 2:
[unicast_master_table]
UDPv6 time_server2 1
UDPv6 time_server3 2
UDPv6 time_server1 3
这确保我们能够在正常工作条件下将负载均匀地分配给所有的时间设备。
我们面临的另一个主要挑战是确保 PTP 与多主机网卡一起工作。多个主机共享同一个物理网络接口,因此是一个 PHC。然而,tp4l 无法做到这一点,而且会对 PHC 进行约束。
一些网卡制造商开发了一种所谓的“自由运行”模式,其中 ptp4l 只是在内核驱动中对公式进行约束。实际的 PHC 不受影响,继续自由运行。这种模式的结果是精度稍差,但它对 tptp4l 完全透明。
其他网卡制造商只支持“实时时钟”模式,当第一个抓住锁的主机实际上是在训练 PHC。这里的好处是更精确的校准和更高质量的保持,但它导致了在使用同一网卡的其他主机上运行的 tp4l 的一个单独问题,因为试图调整 PHC 频率没有影响,导致不准确的时钟偏移和频率计算。
PTP 简介
为了描述数据中心的配置,我们已经开发并发布了一个 PTP 配置文件,它反映了上述的边缘案例和更多的案例。
可替代的 PTP 客户
我们正在评估使用另一种 PTP 客户端的可能性。我们的主要标准是:
- 支持我们的 PTP 简介
- 符合我们的同步质量要求
- 开放源代码
我们正在评估 Timebeat PTP 客户端,截止目前,我们觉得它非常有前景。
持续递增的计数器
在 PTP 协议中,只要我们向客户传递一个 UTC 偏移量,传播时间并不重要。在我们的例子中,它是国际原子时间(TAI),但有些人可能会选择 UTC。我们喜欢把提供的时间看成是一个持续递增的计数器。
在这一点上,我们没有对系统时钟进行调控,tp4l 只用来调控网卡的 PHC。
fbclock
在服务器群中同步 PHC 是件好事,但如果无法在客户端读取和操作这些数字,就没有任何好处。
为此,我们开发了一个简单而轻量级的 API,名为 fbclock,它从 PHC 和 tp4l 收集信息,并公布容易消化的不确定窗口信息。
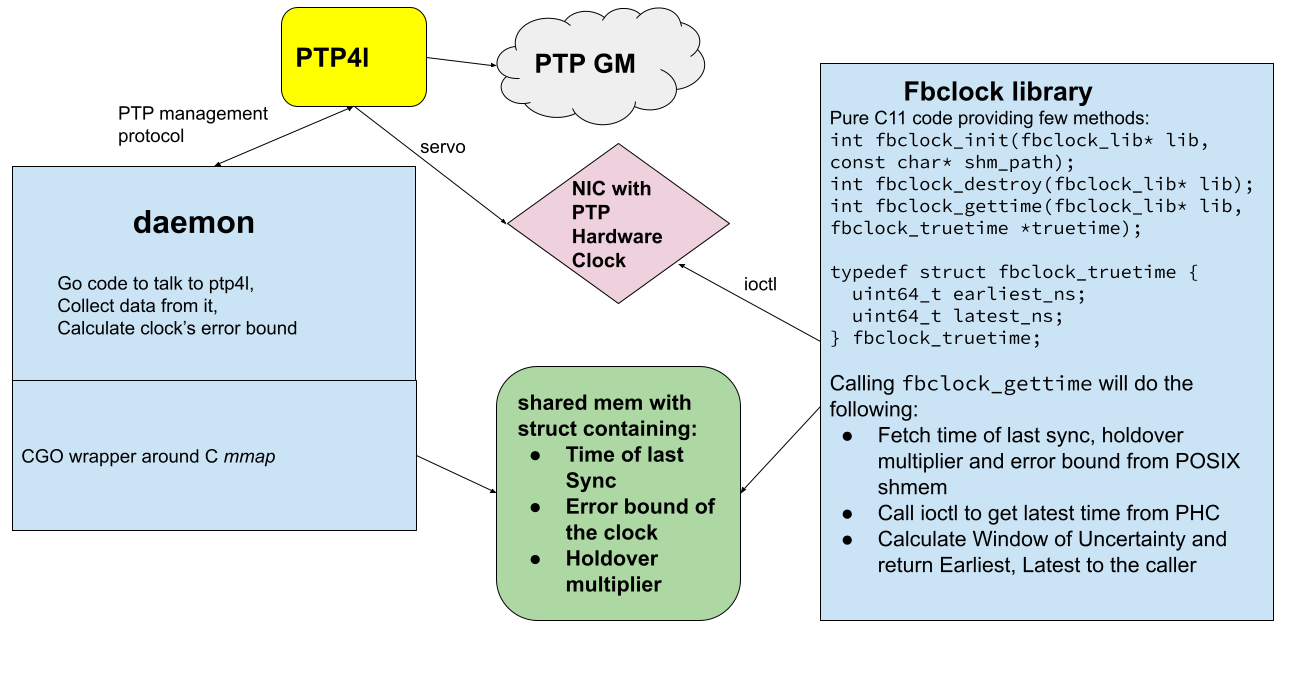
fbclock 通过一个非常有效的 ioctl PTP_SYS_OFFSET_EXTENDED,从 PHC 得到 一个当前的时间戳,从 tp4l 得到最新的数据,然后应用数学公式计算不确定窗口(WOU)。
$ ptpcheck fbclock
{"earliest_ns":1654191885711023134,"latest_ns":1654191885711023828,"wou_ns":694}正如你所看到的,该 API 并不返回当前时间(又称 time.Now())。在这个例子中,我们知道不确定窗口是 694 纳秒,时间在(TAI)2022 年 6 月 2 日星期四 17:44:08:711023134 和 2022 年 6 月 2 日星期四 17:44:08:711023828 之间。
这种方法可以让客户等到间隔期过后,以确保准确的交易排序。
误差约束测量
测量时间的精度(或不确定窗口)意味着,在交付的时间值旁边,提出一个窗口(一个正负值),保证包括真正的时间,达到高度的确定性。
我们有多大的把握是由时间的正确性决定的,而这由具体的应用决定。
我们的案例中,这种确定性要优于 99.9999%(6-9s)。这种可靠性水平下,可以期望在 100 万次测量中出现不到 1 个错误。
误差率估计使用对数据历史的观察(直方图)来拟合一个概率分布函数(PDF)。从概率分布函数中可以计算出方差(取平方根,得到标准差),然后从那里用简单的乘法来得到基于分布值的估计。
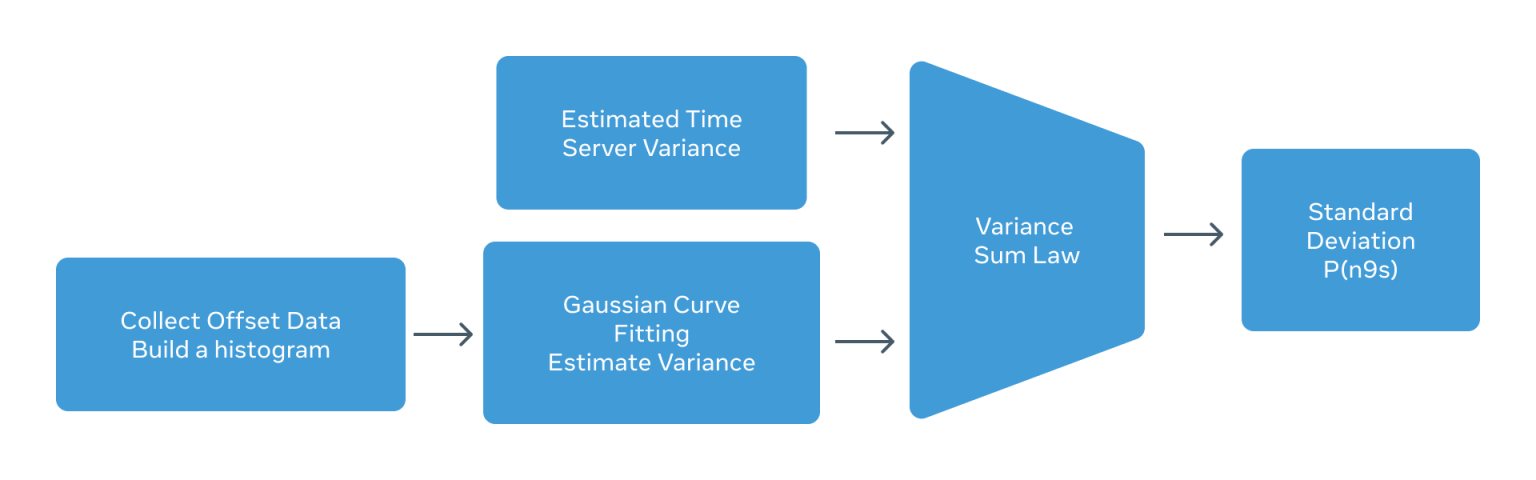
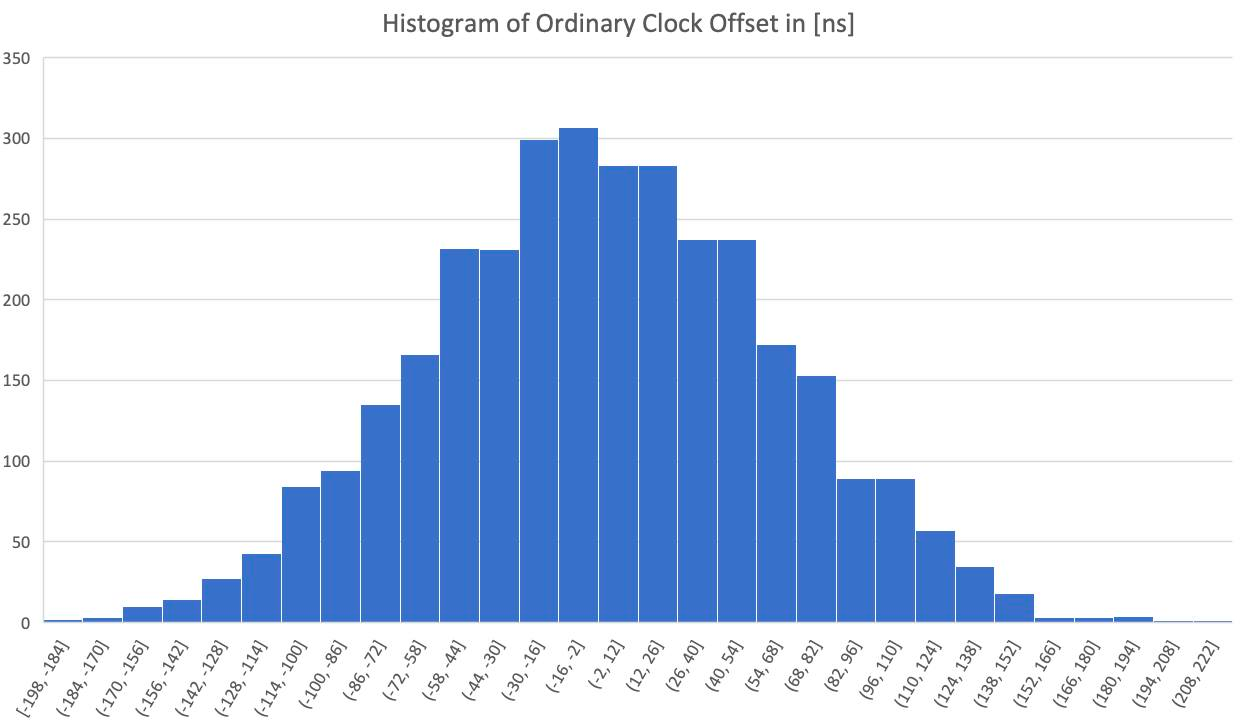
下面是在普通时钟上运行的 ppp4l 的偏移测量的柱状图。
为了估计总方差(E2E),需要知道时间服务器一直到终端节点 NIC 积累的时间误差方差。这包括 GNSS、原子钟和时间卡 PHC 到 NIC PHC(ts2phc)。制造商提供 GNSS 误差方差。在 UBX-F9T 的情况下,它大约是 12 纳秒。对于原子钟来说,这个值取决于我们设置的约束阈值。纪律化阈值越严格,偏移方差越小,但保持性能越低。在运行这个实验的时候,原子钟的误差方差被测量为 43 纳秒(标准偏差,std)。最后,工具 ts2phc 将方差增加了 30 纳秒(std),导致总方差为 52 纳秒。
观察到的结果与通过“方差之和法”得到的计算方差相符。
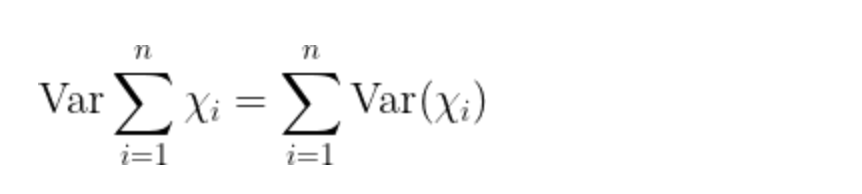
根据方差之和定律,我们所要做的就是把所有的方差加起来。在我们的案例中,我们知道总的观测器 E2E 误差(通过 Calnex Sentinel 测量)约为 92 纳秒。
另一方面,按照我们的估计,可以有以下几点:
估计的 E2E 差异=[GNSS 差异+MAC 差异+ts2phc 差异]+[PTP4L 偏移差异]=[时间服务器差异]+[普通时钟差异]
插入数值:
估计的 E2E 方差=(12ns 2)+(43ns2)+(52ns2)+(61ns2)=8418,相当于 91.7 纳秒。
这些结果表明,通过将误差方差沿着时钟树向下传播,可以很准确地估计 E2E 误差方差。E2E 误差方差可用于计算基于下表的不确定性窗口(WOU)。
简单地说,通过将估计的 E2E 误差方差乘以 4.745,我们可以估计出 6-9s 概率的不确定性窗口。
对于我们给定的系统,6-9 秒的概率约为 92 纳秒 x 4.745 = 436 纳秒这意味着给定一个 PTP 报告的时间,考虑 436 纳秒左右的窗口大小,可以保证包括真实的时间,置信度超过 99.9999%。
对保留者的补偿
虽然上述所有内容看起来很有逻辑性,但它建立在假设上。这个假设是,与开放时间服务器(OTS)的连接是可用的,而且一切都处于正常运行模式。很多事情都可能出错,比如 OTS 瘫痪了,开关瘫痪了,同步信息没有按照它们应该有的行为,中间有什么东西决定唤醒 on-calls 等等。在这种情况下,错误约束计算应该进入保持模式。在这种情况下,同样的事情也适用于 GNSS 下 降时的 OTS。在这种情况下,系统将根据一个复合速率增加不确定窗口。该速率将根据正常操作期间振荡器的稳定性(滚动差异)来估计。在 OTS 上,复合速率由系统的精确遥测监测(温度、振动等)来调整。在校准系数方面有相当多的工作,并达到最佳效果,我们仍在进行这些微调工作。
在网络同步可用期间,伺服机不断调整客户端本地时钟的频率(假设最初的步进导致收敛)。网络同步的中断(由于失去与时间服务器的连接或时间服务器本身发生故障)将给伺服系统留下一个最后的频率校正值。因此,这个值并不是为了估计本地时钟的精度,而是一个临时的频率调整,以减少时钟和时间服务器之间测量的时间误差(偏移)。
因此,有必要首先考虑同步损失期,并使用频率修正的最佳估计值(通常是以前修正值的滚动平均值);其次,通过查看最后一个修正值并与以前修正值的滚动平均值相比较,考虑误差边界的增加。
如何监控 PTP 架构
监控是 PTP 架构中最重要的部分之一。由于该服务的性质和影响,我们花费了相当多的时间来研究工具。
Calnex
我们与 Calnex 团队合作,创建了 Sentinel HTTP API,使我们能够管理、配置和导出设备的数据。我们在 Meta 上创建并开源了一个 API 命令行工具,让用户和脚本友好互动。
使用 Calnex Sentinel 2.0,我们能够监测每个时间设备的三个主要指标——NTP、 PTP 和 PPS。
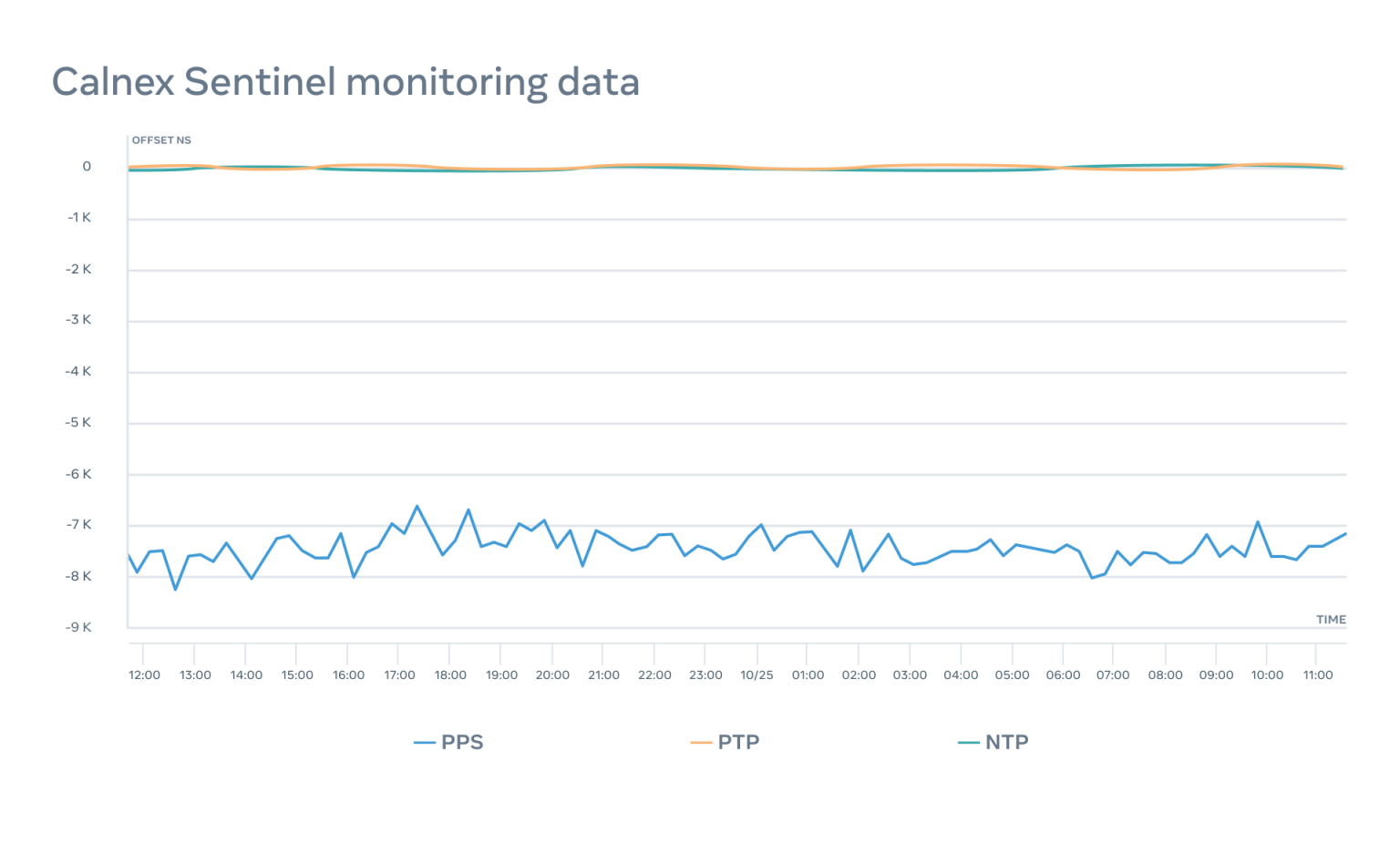
我们能够通知工程师关于电器的任何问题,并精确地检测出问题所在。
例如,在这种情况下,PTP 和 PPS 的监测在 24 小时内的变化大致小于 100 纳秒,而 NTP 保持在 8 微秒以内。
ptpcheck
为了监控我们的设置,我们实施并开源了一个名为 ptpcheck 的工具。它有许多不同的子命令,但最有趣的是以下几个。
diag
客户端子命令提供一个 ptp 客户端的整体状态。它报告了收到最后一条同步信息的时间、到所选时间服务器的时钟偏移量、平均路径延迟以及其他有用的信息:
$ ptpcheck diag
[ OK ] GM is present
[ OK ] Period since last ingress is 972.752664ms, we expect it to be within 1s
[ OK ] GM offset is 67ns, we expect it to be within 250µs
[ OK ] GM mean path delay is 3.495µs, we expect it to be within 100ms
[ OK ] Sync timeout count is 1, we expect it to be within 100
[ OK ] Announce timeout count is 0, we expect it to be within 100
[ OK ] Sync mismatch count is 0, we expect it to be within 100
[ OK ] FollowUp mismatch count is 0, we expect it to be within 100fbclock
客户端子命令,允许查询 fbclock API 并获得当前的不确定性窗口:
$ ptpcheck fbclock
{"earliest_ns":1654191885711023134,"latest_ns":1654191885711023828,"wou_ns":694}sources
Chrony 风格的客户端监控,可以看到客户端配置文件中配置的所有时间服务器,它们的状态和时间质量。
$ ptpcheck sources
+----------+----------------------+--------------------------+-----------+--------+----------+---------+------------+-----------+--------------+
| SELECTED | IDENTITY | ADDRESS | STATE | CLOCK | VARIANCE | P1:P2 | OFFSET(NS) | DELAY(NS) | LAST SYNC |
+----------+----------------------+--------------------------+-----------+--------+----------+---------+------------+-----------+--------------+
| true | abcdef.fffe.111111-1 | time01.example.com. | HAVE_SYDY | 6:0x22 | 0x59e0 | 128:128 | 27 | 3341 | 868.729197ms |
| false | abcdef.fffe.222222-1 | time02.example.com. | HAVE_ANN | 6:0x22 | 0x59e0 | 128:128 | | | |
| false | abcdef.fffe.333333-1 | time03.example.com. | HAVE_ANN | 6:0x22 | 0x59e0 | 128:128 | | | |
+----------+----------------------+--------------------------+-----------+--------+----------+---------+------------+-----------+--------------+oscillatord
服务器子命令,允许从时间卡中读取摘要。
$ ptpcheck oscillatord
Oscillator:
model: sa5x
fine_ctrl: 328
coarse_ctrl: 10000
lock: true
temperature: 45.33C
GNSS:
fix: Time (3)
fixOk: true
antenna_power: ON (1)
antenna_status: OK (2)
leap_second_change: NO WARNING (0)
leap_seconds: 18
satellites_count: 28
survey_in_position_error: 1
Clock:
class: Lock (6)
offset: 1例如,我们可以看到,时间卡上的最后一次修正只有 1 纳秒。
phcdiff
这个子命令允许我们获得任何两个 PHC 之间的差异:
$ ptpcheck phcdiff -a /dev/ptp0 -b /dev/ptp2
PHC offset: -15ns
Delay for PHC1: 358ns
Delay for PHC2: 2.588µs在这种特殊情况下,时间卡和服务器上的网卡之间的差异是 -15 纳秒。
客户端 API
定期或按需触发监测是好事,但我们想更进一步。我们想知道客户端实际经历了什么。为此,我们在 fbclock API 中嵌入了几个基于原子计数器的桶,这些计数器在客户端每次调用 API 的时候都会递增:
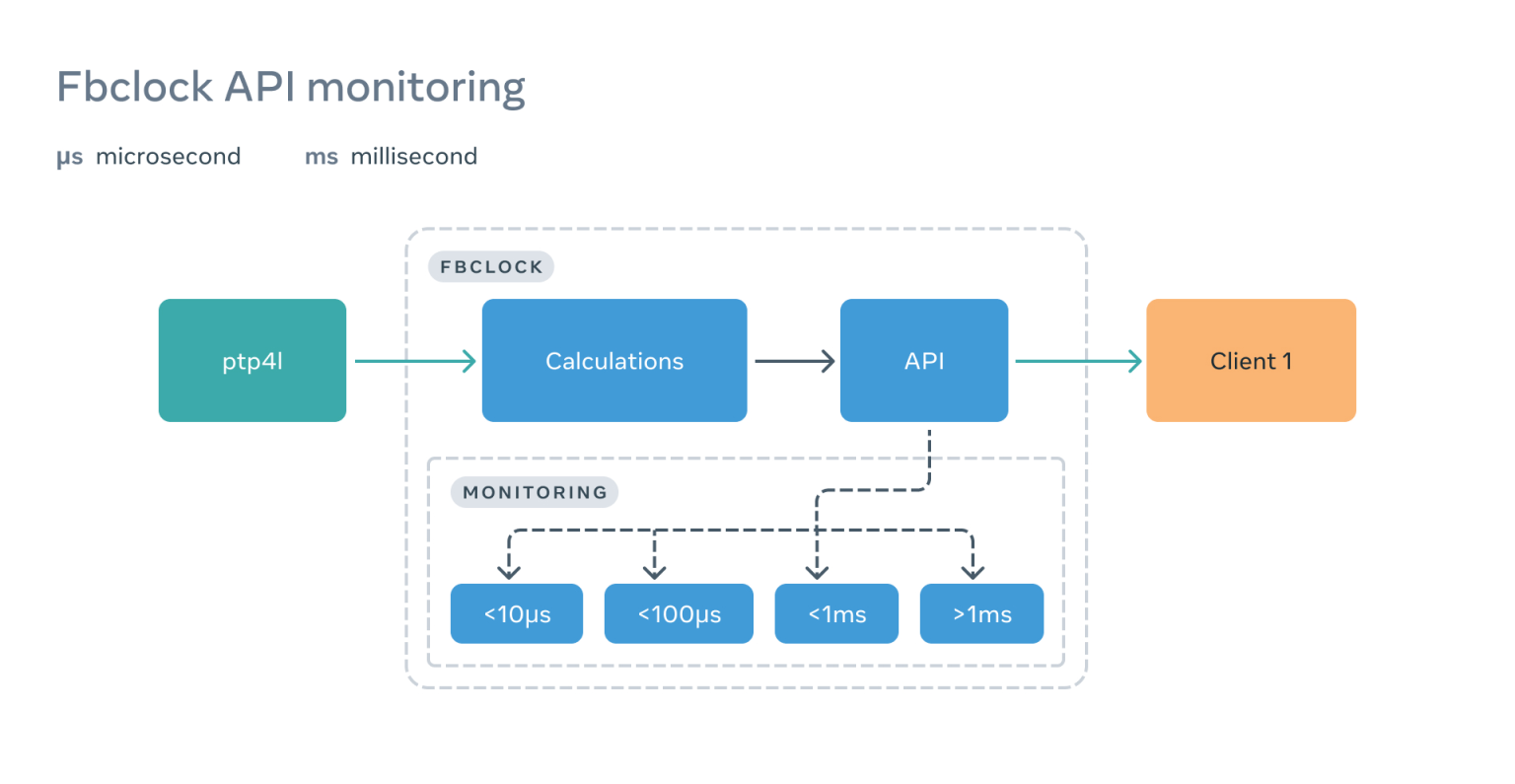
这使我们能够清楚地看到客户何时遇到问题——而且往往是在客户注意到之前。
可线性化检查
PTP 协议(尤其是 tp4l)没有一个法定人数选择过程(与 NTP 和 chrony 不同)。这意味着客户端根据通过 Announce 消息提供的信息来选择和信任时间服务器。即使时间服务器本身是错误的,这也是真的。
对于这种情况,我们实施了最后一道防线,称为可线性化检查。
想象一下这样一种情况:一个客户被配置为使用三个时间服务器,而客户订阅了一个有问题的时间服务器(例如,时间服务器 2)。
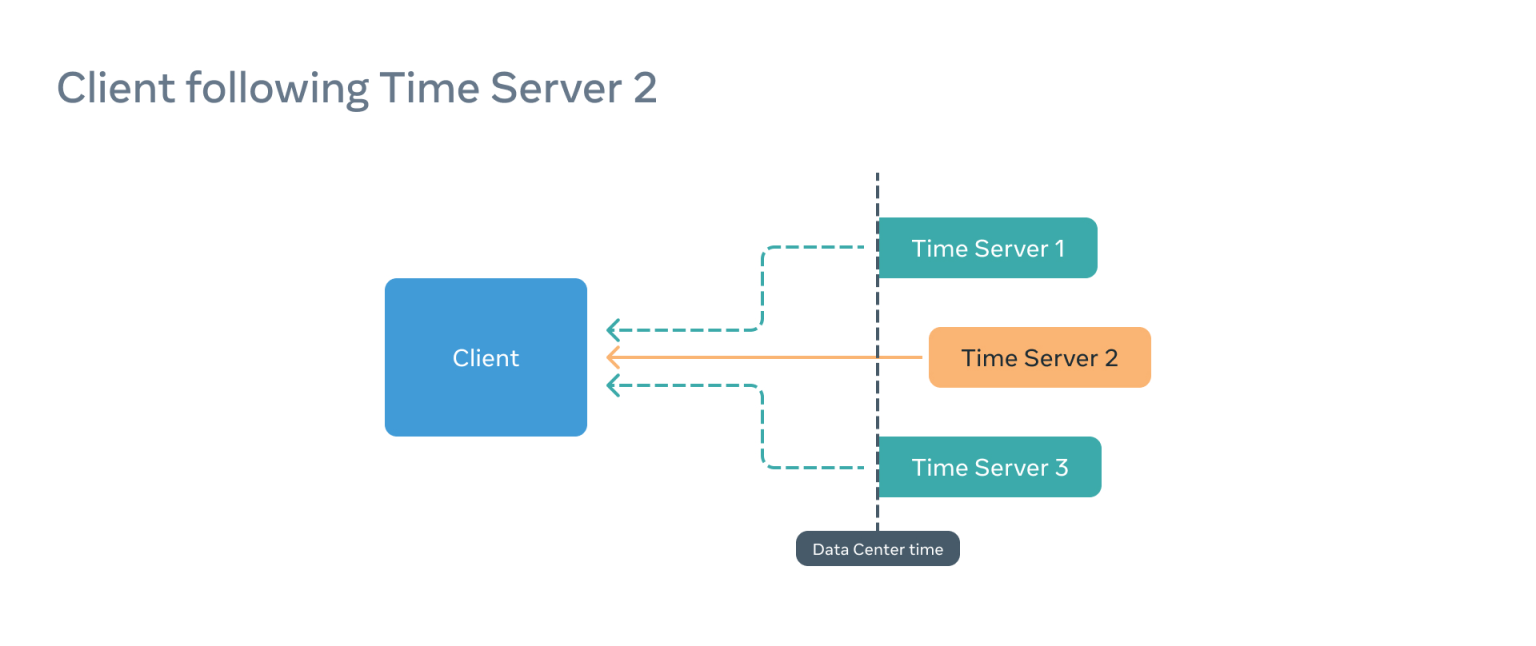
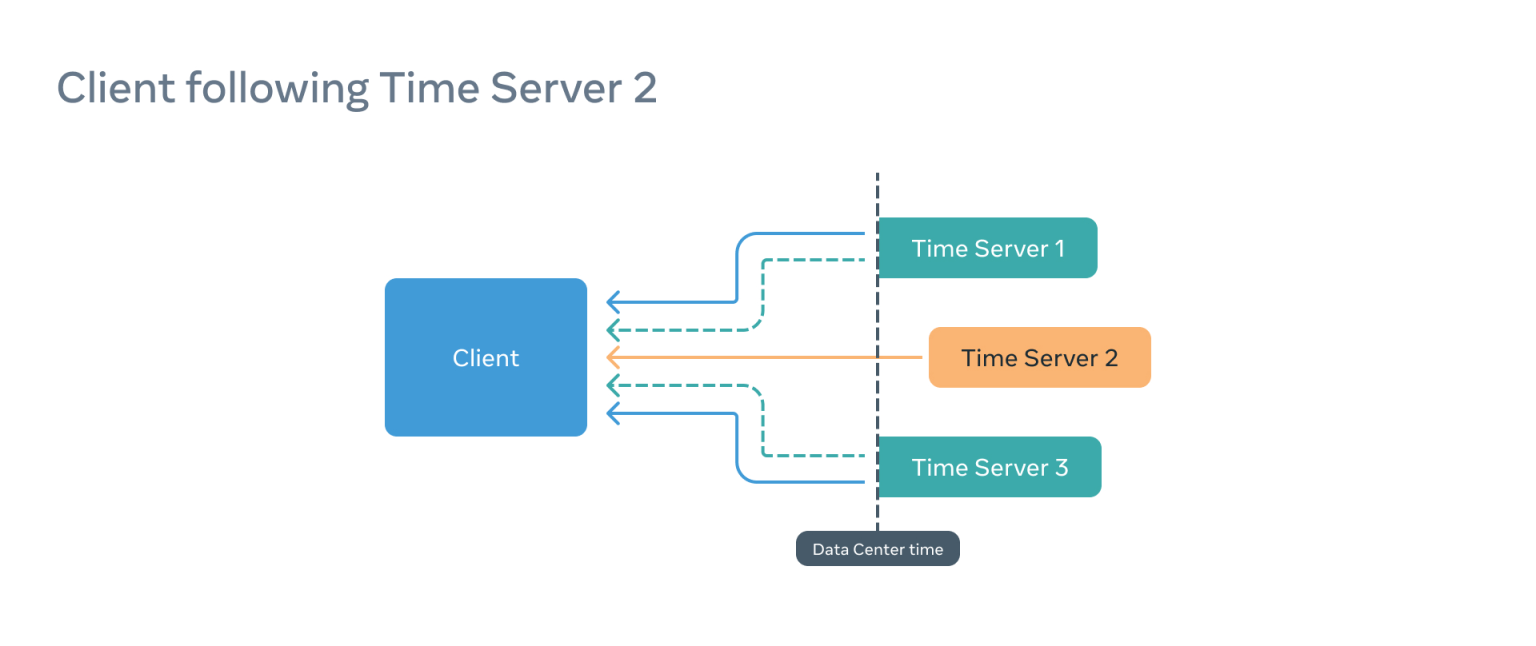
在这种情况下,PTP 客户端会认为一切正常,但它提供给应用消耗时间的信息会不正确,因为不确定窗口将被转移,因此不准确。
为了解决这个问题,在并行的情况下,fbclock 与其余的时间服务器建立了通信,并比较了结果。如果大部分的偏移量都很高,这意味着我们的客户所跟随的服务器是离群的,客户是不可线性化的,即使时间服务器 2 和客户之间的同步是完美的。
PTP 的重要性
我们认为,未来的几十年里,PTP 仍会是计算机网络中保持时间的标准。这就是为什么我们要以前所未有的规模来部署它。我们必须对整个基础设施堆栈(从 GNSS 天线到客户端 API)进行严格审查。多数情况下,我们甚至得从零开始搭建。
随着我们继续推广 PTP,我们希望更多生产网络设备的厂商能够利用我们的工作,帮助把支持 PTP 的新设备带到行业中。我们已经将我们的大部分工作开源,从我们的源代码到我们的硬件,我们希望业界能够加入我们,将 PTP 带到世界。 所有这些都是以提高现有解决方案的性能和可靠性的名义进行的,但也着眼于在未来开辟新的产品、服务和解决方案。
感谢参与这项工作的所有人,包括 Meta 的内部团队和合作的供应商和制造商。特别感谢 Andrei Lukovenko。
我们的旅程才刚刚起步!
原文作者:Oleg Obleukhov, Ahmad Byagowi
原文链接:https://engineering.fb.com/2022/11/21/production-engineering/precision-time-protocol-at-meta/







