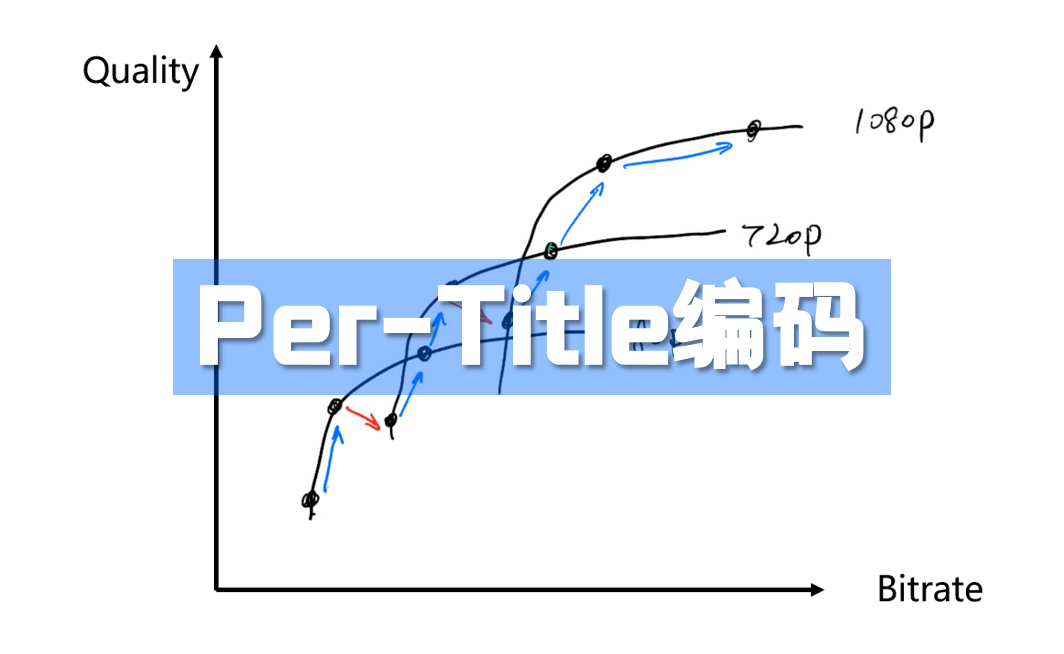
什么是视频编码?简单来说,编码是将原始音视频内容的格式压缩和转换为数字文件或格式的过程,这反过来会使视频内容兼容不同的设备和平台。编码的主要目标是压缩内容以占用更少的空间。我们通过删除无用的信息来做到这一点,也称为有损过程。播放内容时,它会作为原始内容的近似值播放。当然,删除的内容信息越多,播放的视频与原始视频相比就越差。视频编码的过程是由编解码器强加的,我们将在这篇文章中进行详细讨论。
为什么编码很重要?
视频编码很重要,因为它使我们能够更轻松地通过互联网传输视频内容。在视频流中,编码至关重要,因为原始视频的压缩减少了宽带,使其更易于传输,同时仍为最终观众保持良好的体验质量。如果不压缩所有视频内容,Internet 上的可用宽带将不足以传输所有内容,并阻止我们部署广泛的分布式视频播放服务。即使宽带较低,我们也可以在家中的多个设备上流式传输视频,使用移动设备随时随地,甚至在在全球任何地方与亲人进行音视频聊天,这都归功于视频编码。
运动补偿
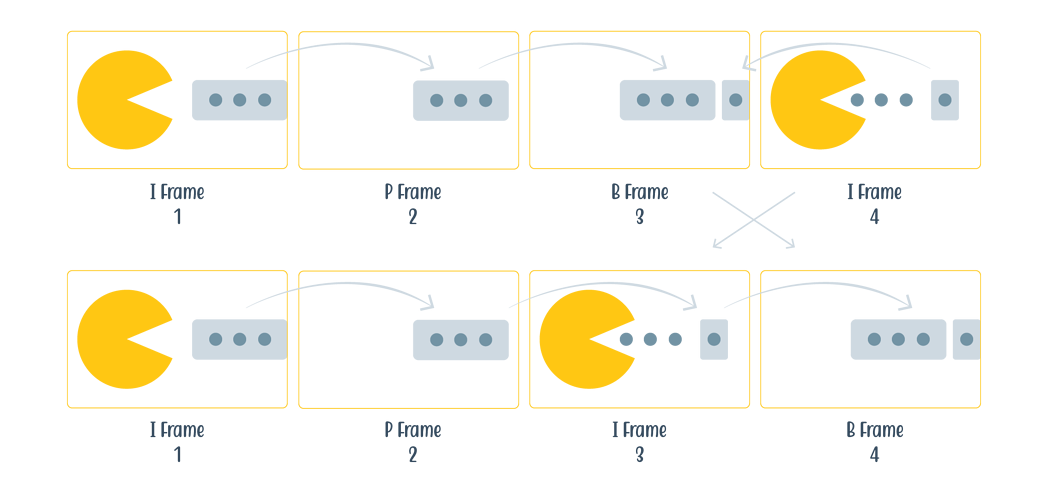
在视频编码中,运动非常重要。我们最常在 I 帧(或关键帧)、P 帧和 B 帧中表达这一点。关键帧存储整个图像。在下一帧或 P 帧中,当注意到没有太多移动或变化时,P 帧可以参考前一个关键帧,因为只有一些像素移动了。I、P 和 B 帧共同组成一组图片(GOP),并且该组中的帧只能相互引用,而不能引用其外部的帧。对于没有大量运动的帧,这可以节省大约 90% 的数据存储,你需要存储常规图像(如果它使用像 PNG 文件那样的无损数据压缩),这些数据非常大。
宏块
宏块存在于每一帧里。每个块都有特定的大小、颜色和运动信息。这些块在某种程度上是分开编码的,有利于正确的并行化。以前,诸如 H.264 之类的编解码器仅允许 4x4 样本或 8x8 样本的块大小,但是较新的编解码器现在允许更多的块大小以及矩形形式。当块中不需要很多细节时,可以使用大块,因为使用大块比使用小块更节省空间。
宏块由多个组件组成。有一些子块,其目的是提供像素颜色信息。还有一些子块提供与前一帧相比的运动补偿矢量。由于这种宏块结构,在低宽带情况下,视频内容中可能会出现明显的边缘或“块状”。有一些方法可以通过添加一个过滤器来平滑这些边缘。该过滤器称为“内环”过滤器,用于编码和解码过程,以确保视频内容与源素材保持接近。
色度子采样
在大多数情况下,我们在 RGB 通道中划分颜色,但是,人眼检测亮度变化的速度比颜色变化的速度要快得多,尤其是在运动图像中。因此,在音视频中,我们使用称为 YCbCr 的不同颜色空间。这个色彩空间分为:
- Y(亮度或亮度)
- Cb(蓝差色度)
- Cr(红差色度)
- 亮度 = 亮度,色度 = 颜色
在色度子采样中,我们在 Y 通道和 CbCr 通道中分割图像。例如,我们从一张图像中获取一个两行网格,每行四个像素 (4x2)。在二次抽样中,我们将比率定义为j![]() b。
b。
j:采样的像素数量(即网格宽度)
a:第一行的颜色数量(CbCr)
b:与第一行相比,第二行的颜色 (CbCr) 变化量。
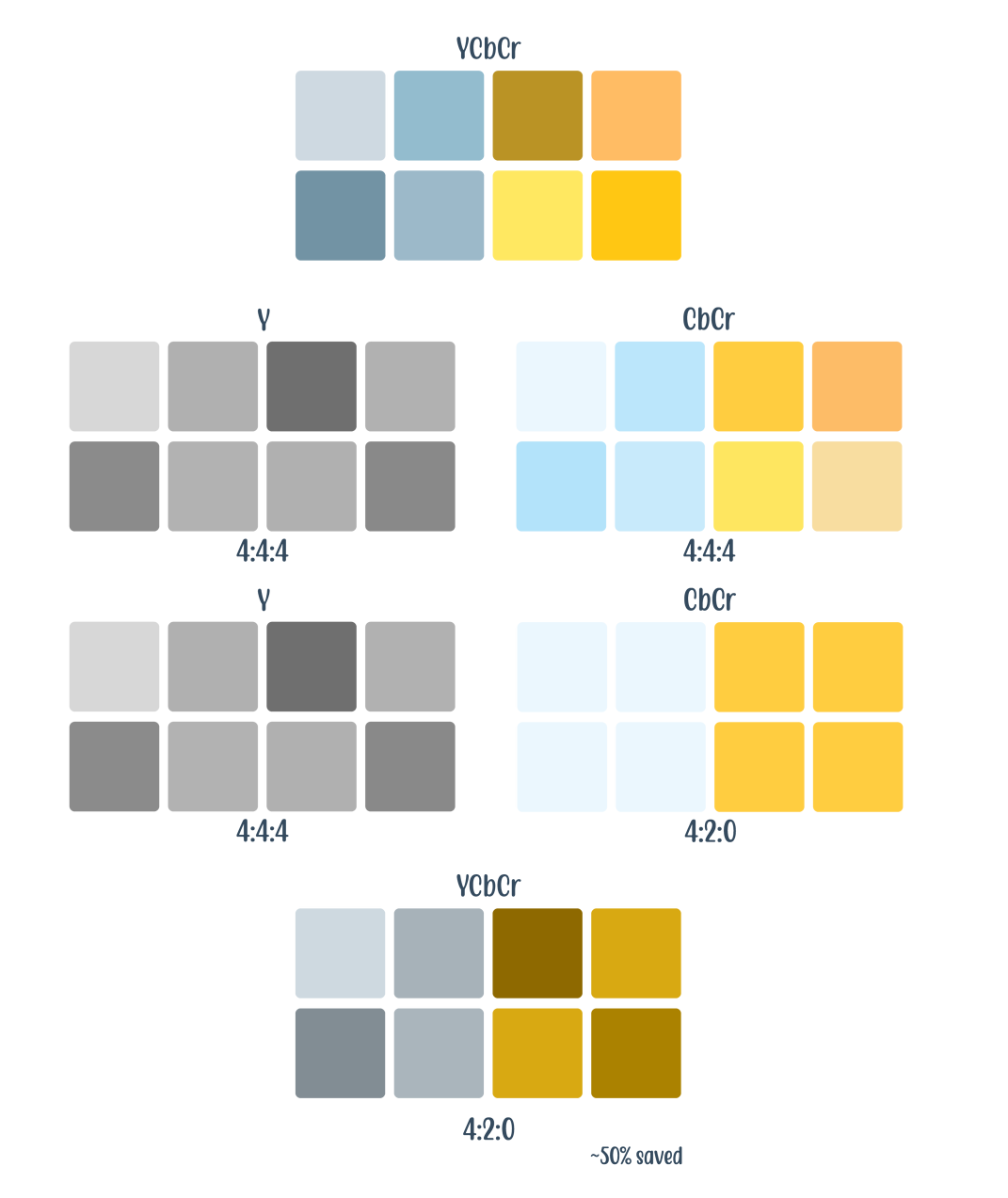
在流媒体视频中,4:4:4 是全色空间。将其减少到 4:2:2 可节省 30% 的空间,进一步减少到 4:2:0 可节省 50% 的空间。在视频流中(想想你的 Netflix 和 Hulu 电视节目),最常用和最广泛使用的是 4:2:0。然而,在视频编辑领域,4:4:4 是最常见的。
量化
在讨论视频编码时,我们指的不仅仅是通过图像组件节省空间,还包括音频组件。音频是连续的模拟信号,但为了编码,我们需要将其数字化。音频数字化后,我们将其拆分为多个正弦波或正弦波,每个正弦波代表一个音频频率。为了节省空间,我们可以丢弃不需要的频率。
如果我们拍摄一张图像,我们还可以将一排排像素视为一个大信号。就像音频一样,我们删除图像中的频率,称为频域掩蔽。删除频率确实会导致细节丢失,但你可以删除适当数量的频率,这会使最终查看者不会注意到它,这个过程称为量化。
什么是编解码器?
编解码器本质上是视频内容压缩的标准。编解码器由两个组件组成,一个是压缩内容的编码器,一个是解压缩视频内容并播放原始内容的近似值的解码器。一个编码器和一个解码器,因此得名编解码器。
音频编解码器
对于音频,AAC 被视为业界事实上的标准。AAC 基本上在哪里都行得通,并且拥有最大的市场份额。其他音频编解码器包括:Opus、Flac 和 Dolby Audio。Opus 在语音方面表现出色,也被 YouTube 使用,看似是仅使用Opus进行大型服务,但最后它仍然败给了 AAC。杜比音频(也称为 AC3)有时仍用于环绕声,因为一些较旧的环绕声系统不播放 AAC。
视频编解码器
H.264/AVC:
H.264,也称为 AVC(高级视频编码)或 MPEG-4 AVC,于 2003 年标准化。该编解码器由 MPEG 和 ITU-T VCEG 在称为 JVT(联合视频团队)的合作伙伴关系下开发。它几乎在任何地方、任何设备上都得到支持,同时仍能提供高质量的视频流,并被视为新编解码器的基准。关于版税费用也相对较低。
H.265/HEVC
H.265,也称为 HEVC,代表高效视频编码,是 MPEG 和 ITU-T VCEG(在称为 JCT-VC 的合作伙伴关系下)的标准。该编解码器于 2013 年首次标准化,并最终从 2014 年扩展到 2016 年。 H.265 的目标是与 H.264 相比将内容压缩提高 50%,同时保持相同的质量。
Netflix 的一项研究表明,与 H.264 相比,性能提高了 35-53%,与 VP9 相比,性能提高了 17-21%。
*** *请记住,编码器、内容等对于此类比较非常重要。
这些改进是通过优化 H.264 中已有的技术实现的。本质上,H.265 将内容压缩成比 H.264 更小的文件,作为回报,降低了播放音视频内容所需的宽带。尽管这都是好消息,但 H.265 仍然很少使用。为什么呢?主要问题是许可和版税的不确定性。
VP9:
VP9 是 VP8 的继任者,由 Google 旗下的 On2Technologies 开发。VP9 于 2013 年标准化。此编解码器类似于 HEVC,但不需要版税。业内人士在使用 VP9 时遇到的困难在于,虽然它在所有主要浏览器和安卓设备上得到广泛支持,但 Apple 或任何 Apple 设备都不支持它。相反,它们支持 H.264 和 H.265。
AV1:
2015年,开放媒体联盟(AOMedia)成立。在此期间,Google 正在开发 VP10,Mozilla (Xiph) 正在开发 Daala,而 Cisco 正在开发 Thor。他们没有创建三个独立的编解码器,并因版税的限制而感到沮丧,最后决定加入,因此创建了 AV1。他们共同的目标是实现比之前 VP9 中显示的效率高 30%,但就像 VP9 一样,也保持免版税。所有 AOMedia 成员都提供了他们的相关专利,为专利辩护计划做出贡献。
虽然 AV1 编解码器已完成,但仍有工作要做,但似乎该编解码器已开始被大型行业参与者采用,并将在未来继续采用。
编解码器的未来
编解码器的当前状态似乎相对简单:音频的 AAC 和 H.264 是更广泛的覆盖范围所必需的。H.264 是旧设备的后备,VP9 没有 iOS 支持,而 AV1 在投入正常生产和使用之前还有很长的路要走。那么在只有一种编解码器不够用的情况下,有什么解决方案呢?在这些情况下,多编解码器方法是必须的。例如,当今最流行的音视频直播服务 Twitch 目前使用 H.264 和 VP9,但希望将来能切换到 AV1。
另一个例子是 Netflix,他们最近刚刚宣布他们已经开始在他们的 Android 应用程序上流式传输 AV1,其压缩效率比 VP9 提高了 20%。但是,它仅在 CPU 功率比带宽便宜的地方启用,例如当观众通过 4G 进行流式传输时。Netflix 的目标是将来在所有平台上使用 AV1。
VVC
多功能视频编码或 VVC 是 MPEG 的新标准。VVC 的目标是实现比 HEVC 高 50% 的效率以及其他改进。然而,实际上,大多数人预计效率会比 HEVC 高 30-40%。VVC 将为游戏和屏幕共享、360º 视频和视频中的分辨率切换提供更好的支持。
电动汽车
基本视频编码或 EVC 是 MPEG 的另一个新标准,其目标是实现与 HEVC 相同或相似的效率。EVC 将适用于实时编码和解码。该标准专为流媒体 VOD 和实时 OTT 流媒体的离线编码而制定,旨在成为“许可友好”的编解码器。
混合编解码器
混合编解码器本质上是在另一个编解码器之上工作的编解码器。该过程通常遵循以下步骤:
常规步骤:
- 拍摄输入视频
- 在视频上使用专有的缩减器(例如从 1080p 到 480p)
- 编码缩小的视频
- 解码播放器上的视频
- 使用专有升频器升频解码图像
这通常会导致比特率降低 20-40%。
P+(以前称为 PERSEUS Plus)
由 V-Nova 创建的 P+ 今天正在被积极使用。例如,在 H.264 编解码器之上使用这种混合编解码器可以减少 30-50% 的宽带。Perseus 的优势在于可以节省 HEVC 的规模,而无需重做整个编码管道,并且在 iOS 和 Android 上也有硬件解码。话虽如此,在网络上使用 P+ 进行解码可能具有挑战性,会耗尽电池电量,并且目前不适用于 DRM,但这种情况将会改变。这种混合编解码器目前更名为 LCEVC,一旦集成到硬件中,它或许可以与 DRM 一起使用。
增强播放器
ENHANCEplayer 是 Artomatix 和 THEO Technologies 之间的一个联合且仍在进行中的创新项目。混合编解码器利用 Artomatix 的“Artomatix Enhance AI”来提升图像分辨率、消除压缩伪影并消除噪音。这实质上意味着使用神经网络 (NN) 或 AI 生成“超分辨率”。神经网络经过训练以增强图像并添加在压缩过程中丢失的细节。目标是达到 40ms 以获得 25fps 的帧率。最大的挑战是保真度,这意味着压缩前的图像在增强后是一样的,在 DRM 发挥作用的情况下仍然很难做到。
你是否有更多关于视频编码的问题或者想了解更多?清与我们的THEO 专家联系以获取个性化信息和建议。
原文链接 https://www.theoplayer.com/blog/basics-of-video-encoding