


5 月 15 日,声网Agora 高级架构师高纯参加了 WebAssambly 社区举办的第一场线下活动“WebAssembly Meetup”,并围绕声网Agora 在 Web 实时视频人像分割技术的应用落地,分享了实践经验。以下为演讲分享整理。
RTC 行业在近几年的发展日新月异,在线教育、视频会议等场景繁荣蓬勃。场景的发展也给技术提出了更高的要求。于是,机器学习越来越多地应用到了实时音视频场景中,比如超分辨率、美颜、实时美声等。这些应用在 Web 端也存在同样的需求,同时也是所有音视频开发者面对的挑战。所幸 WebAssembly 技术为 Web 高性能计算提供了可能。我们首先围绕 Web 端的人像分割应用进行了探索实践。
视频人像分割都用在什么场景?
提到人像分割,我们首先想到的应用场景,就是在影视制作中的绿幕抠图。在绿幕环境下拍摄视频后,经过后期制作,将背景替换成电脑合成的电影场景。
另一种应用场景大家应该都见过。在 B 站上,你会发现有些视频的弹幕不会遮挡画面上的人物,文字会从人像的后面穿过。这也是基于人像分割技术。
以上列举的人像分割技术都是在服务端实现的,而且不是实时音视频场景。
而我们声网做的人像分割技术适用于视频会议、在线教学等实时音视频场景。我们可以通过人像分割技术,可以对视频的背景进行模糊处理,或替换视频背景。
为什么这些实时场景需要这项技术呢?
最近的一项研究发现,在平均 38 分钟的电话会议中,有整整 13 分钟的时间被浪费在处理干扰和中断上。从在线面试、演讲和员工培训课程到集思广益、销售推介、IT 协助、客户支持和 网络研讨会,所有这些情况都面临同样的问题。因此,使用背景模糊或从自定义和预设的许多虚拟背景选项中选择一个,可以大大减少干扰。
还有一项调查显示,有 23% 的美国员工表示视频会议让他们感到不舒服;75% 的人表示他们仍然更喜欢语音会议,而不是视频会议。这是由于人们不希望将自己的居住环境、隐私暴露在公众视野中。那么通过替换视频背景,就可以解决这个问题。
目前,实时音视频场景下的人像分割、虚拟背景,大多是运行在原生客户端上的。只有 Google Meet 利用 WebAssembly 实现过在 Web 实时视频中的人像分割。声网的实现是结合机器学习、WebAssembly、WebGL 等技术实现的。
Web 实时视频虚拟背景的实现
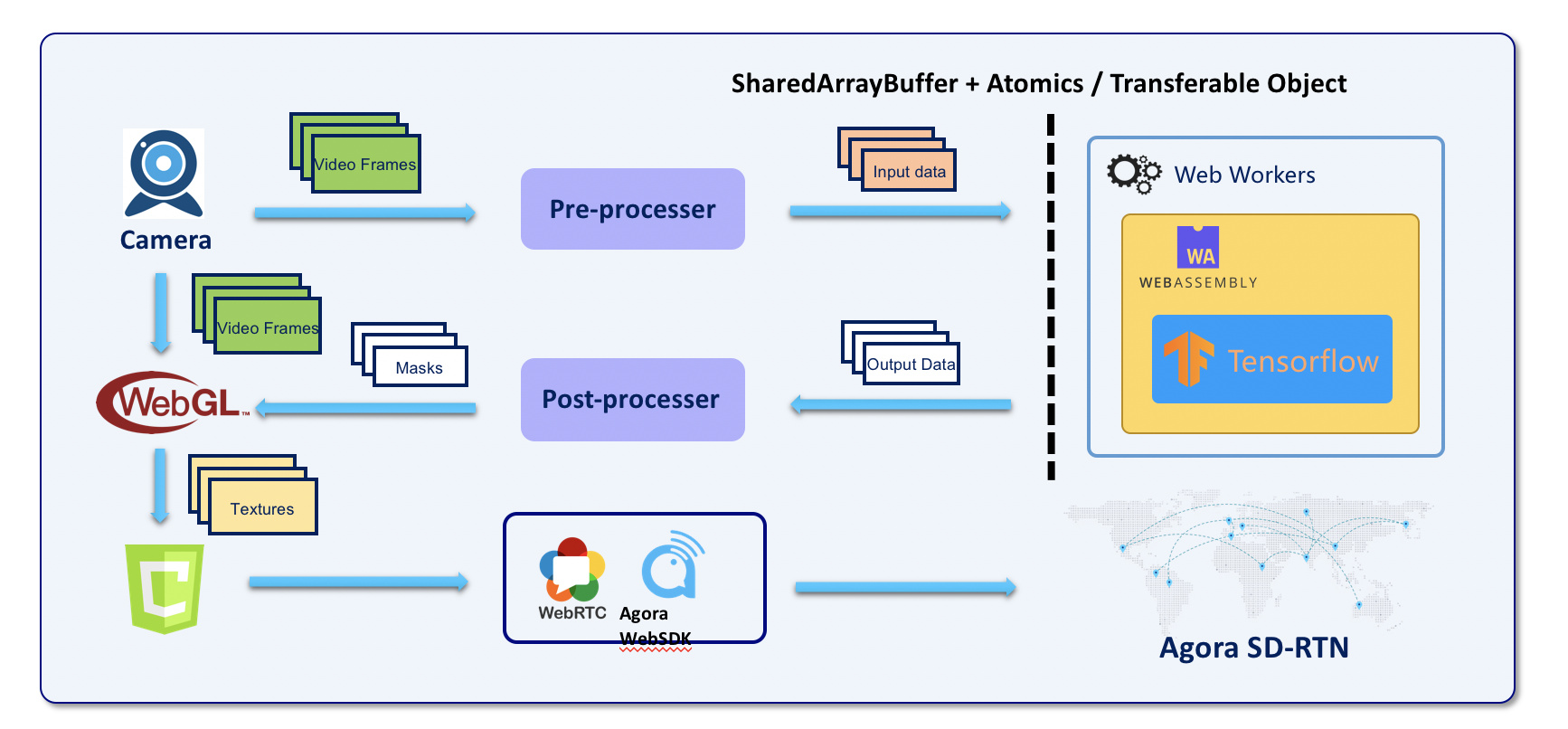
人像分割的技术组件和实时处理流程

在做 Web 的人像分割时,我们还会需要用到这些组件:
- WebRTC:做音视频的采集和传输。
- TensorFlow:作为人像分割模型的框架。
- WebAssembly:做人像分割算法的实现。
- WebGL:GLSL 实现图像处理算法,来处理人像分割后的图像。
- Canvas: 最终渲染视频和图像结果。
- Agora Web SDK:进行实时的音视频传输。
人像分割的实时处理流程是这样的。首先会利用 W3C 的 MediaStream 的 API 进行采集。然后数据会交给 WebAssembly 的引擎去进行预测。因为机器学习的运算开销较大,这就要求输入的数据不能太大,所以需要在输入到机器学习框架前对视频图像做一些缩放的处理或归一化。运算结果从 WebAssembly 输出后还要进行一些后处理,然后再传递给 WebGL。WebGL 会通过这些信息与原始视频信息来做滤波、叠加等处理,最后生成出的结果。这些结果会到 Canvas 上,然后通过 Agora Web SDK 来进行实时传输。
机器学习框架的选择
我们在做这样的人像分割之前,肯定会考虑是不是有现成的机器学习框架。目前可用的包括 ONNX.js、TensorFlow.js、Keras.js、MIL WebDNN 等。它们都会采用 WebGL 或 WebAssembly 作为运算后端。但是在尝试这些框架的时候,都发现了一些问题:
1.缺少对模型文件的必要保护。一般在运行的时候会让浏览器从服务端把模型加载过来。那么模型会直接暴露在浏览器客户端上。这不利于知识产权保护。
2.通用 JS 框架 IO 设计未考虑实际场景。比如 TensorFlow.js 的输入是通用数组,在运算的时候会将内容包装成 InputTensor,然后交给 WebAssembly 或上传为 WebGL 纹理来处理。这个过程相对复杂,在处理对实时性要求很高的视频数据时性能得不到保障。
3.算子支持不完善。通用框架或多或少会缺少可以处理视频数据的算子。
对于这些问题,我们的解决策略是这样的:
1.实现原生机器学习框架的 Wasm 移植。
2.对于没有实现的算子,我们通过定制来补齐。
3.性能方面,我们用 SIMD (单指令多数据流的指令集)和多线程来进行优化。
视频数据预处理
数据的预处理需要对图像进行缩放。在前端一般有两种方式来做:一种是用 Canvas2D,另一种是使用 WebGL。
通过 Canvas2D.drawImage()把 Video 元素里的内容画到 Canvas 上,然后用 Canvas2D.getImageData() 来获取你需要缩放的图像尺寸。
WebGL 本身可以将 Video 元素本身作为一个参数上传成为纹理。WebGL 也提供了从 FrameBuffer 里读取 Video 数据的能力。
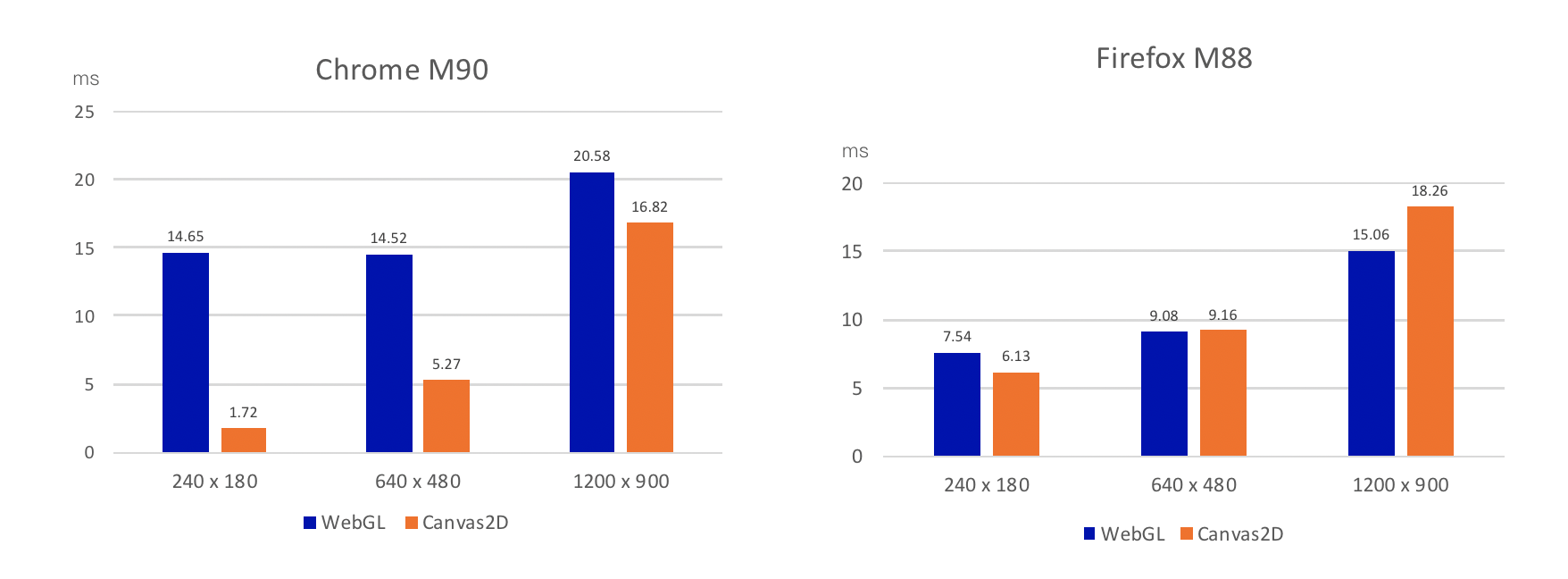
我们也对这两种方法的性能进行了测试,如下图所示,在 x86_64 window10 的环境下,在两种浏览器上,分别测试了三种分辨率的视频在Canvas2D 和 WebGL 上的预处理时间开销。你可以从中判断出在针对不同分辨率的视频进行预处理时,应该选用的方法。
Web Workers 及多线程问题
由于 Wasm 计算开销过大,会导致 JS 主线程阻塞。而且当遇到一些比较特殊的情况,比如进入一家咖啡馆,附近没有电源,那么设备就会处于低能耗模式,这时候 CPU 会降频,从而可能引起的视频处理丢帧。
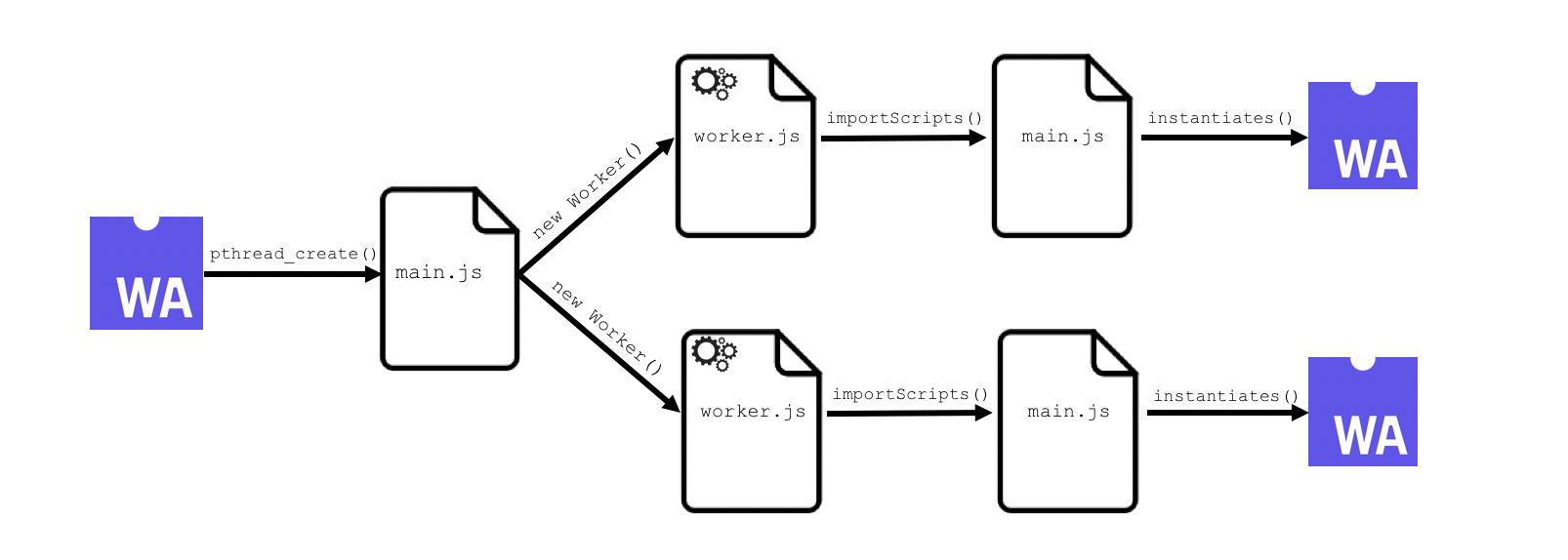
所以,我们要提升性能。在这里,我们用到的是 Web Workers。我们将机器学习推理运算运行在 Web Worker 上,能有效减少 JS 主线程的阻塞。
使用方法也比较简单。主线程来创建 Web Worker,它会在另一个线程上运行。主线程通过 worker.postMessage 给它发消息,让 worker 来访问。(如下述代码示例)

但这也可能会引入一些新的问题:
- postMessage 数据传输带来的结构化拷贝开销
- 共享内存带来的资源竞争及 Web 引擎兼容性
针对这两个问题,我们也做了一些分析。
当传输数据的时候,你的数据是 JS原始数据类型、ArrayBuffer 、 ArrayBufferView、lImageData,或 File / FileList / Blob,或 Boolean / String / Object / Map / Set 类型的时候,那么 postMessage 会使用结构化克隆算法进行深拷贝。
我们在 JS 主线程和 WebWorkers 之间或不同 page 之间进行数据传输的性能测试。如下图所示,测试环境是 x86_64 window10 的电脑。测试结果如下:
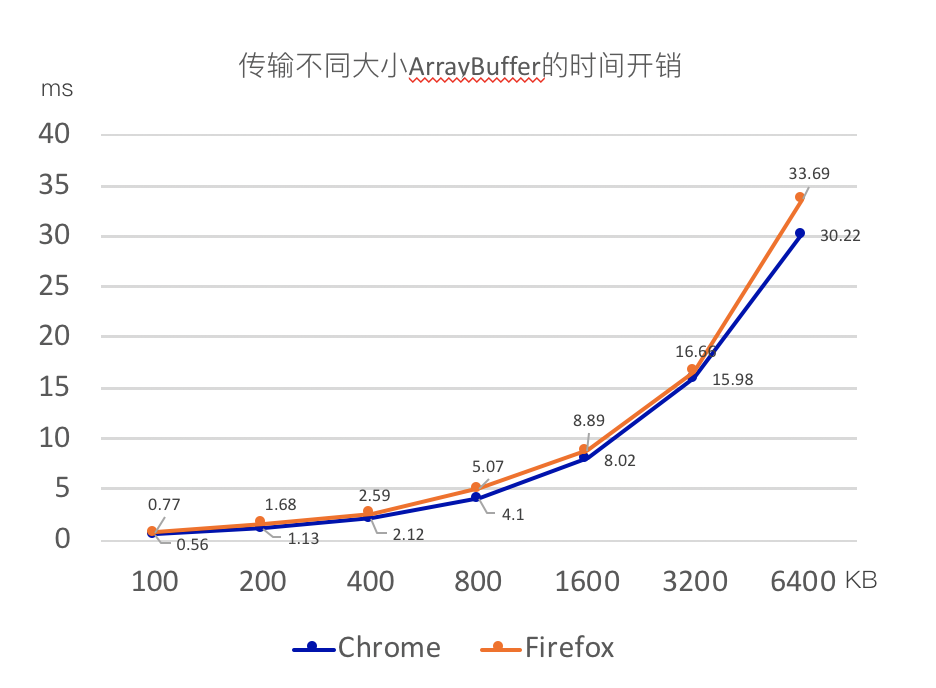
我们预处理后的数据大概在 200KB 以下,所以可以从上图对比看出,时间开销会在 1.68ms 以下。这种性能开销几乎可以忽略不计。
如果你想要避免结构化拷贝,那么可以采用 SharedArrayBuffer。顾名思义,SharedArrayBuffer 原理是让主线程与 Worker 共享一块内存区域,做到同时存取数据。
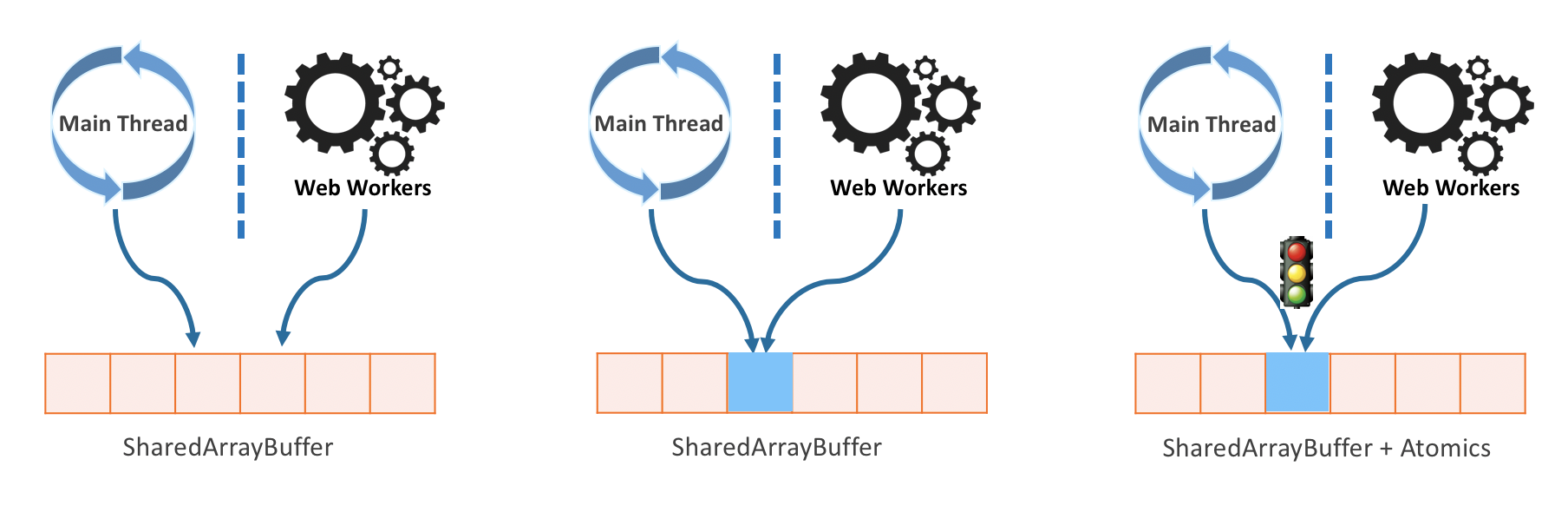
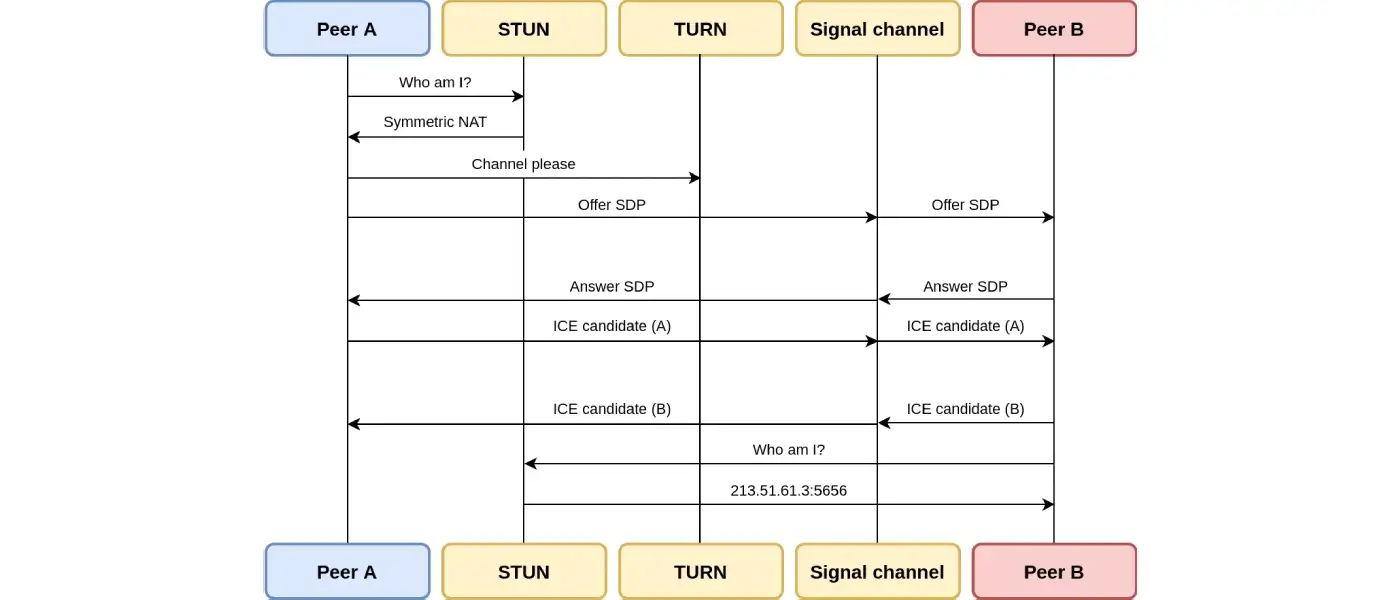
但是与所有的共享内存方法一样(包括原生的),SharedArrayBuffer 也会出现资源竞争的问题。那么这时候就需要 JS 引入额外的机制来处理竞争。JavaScript 中的 Atomics 就是为解决这个问题而诞生的。
我们声网在做人像分割的时候也尝试过 SharedArrayBuffer,也发现了它还会引发一些问题。首先一点就是兼容性问题。目前只有 Chrome 67 版本以上能使用 SharedArrayBuffer。
要知道,在 2018 之前,Chrome、Firefox 两个平台都支持 SharedArrayBuffer,但是 18 年所有 CPU 都被爆出了两个严重漏洞,Meltdown 和 Spectre,它们会导致进程之间的数据隔离被打破,于是两个浏览器就禁用了 SharedArrayBuffer。直到 Chrome 67 做了站点上的进程隔离之后,才又开始允许使用 SharedarrayBuffer。
另一个问题就是开发难度比较高。为解决资源竞争引入的 Atomics 对象使前端开发难度不亚于原生语言的多线程编程。
WebAssembly 模块的功能与实现策略
WebAssembly 主要负责人像分割。我们要实现的主要功能以及实现策略如下:
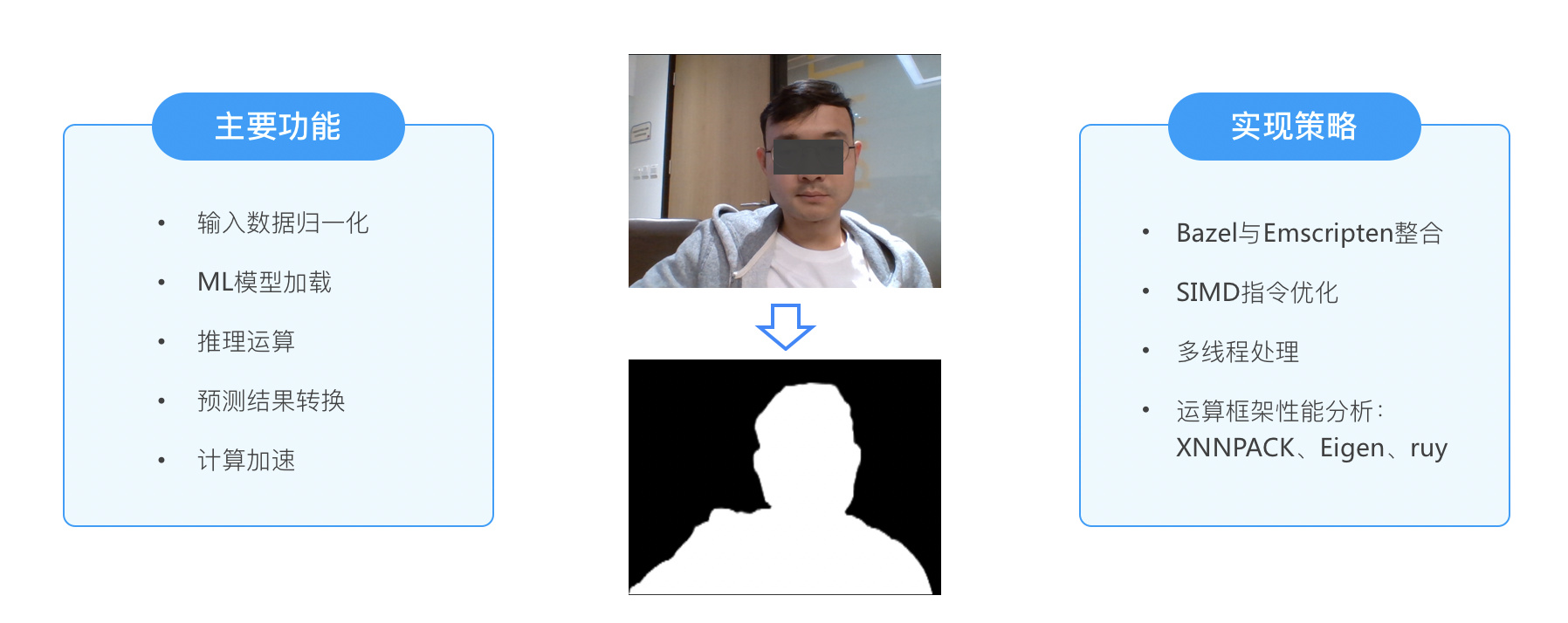
其中,机器学习模型会有不同的向量、矩阵的运算框架。以 TensorFlow 为例,它有三套运算框架:XNNPACK、Eigen、ruy。实际上它们在不同平台上的性能都有差异。我们对此也进行了测试。在 x86_64 window10 环境下的测试结果如下。可以明显看到在我们的处理场景下 XNNPACK 的表现是最好的,因为它是专门针对浮点运算进行了优化的运算框架。

这里我们只是展示了 x86 下的运算测试结果,并不能代表所有平台上的最终结果。因为 ruy 这个框架是 TensorFlow 在移动平台上的默认运算框架,它对 ARM 架构优化更好。所以我们也在别的不同平台上进行了测试。这里就不做一一分享了。
WASM 多线程
开启 WASM 多线程可将 pthread 映射到 Web Workers,将 pthread mutex 方法映射到 Atomics 方法。在开启多线程之后,人像分割场景在 4 线程时性能提升达到最大值,提升幅度达到了 26%。线程的使用不是越多越好,因为本身会有调度开销。
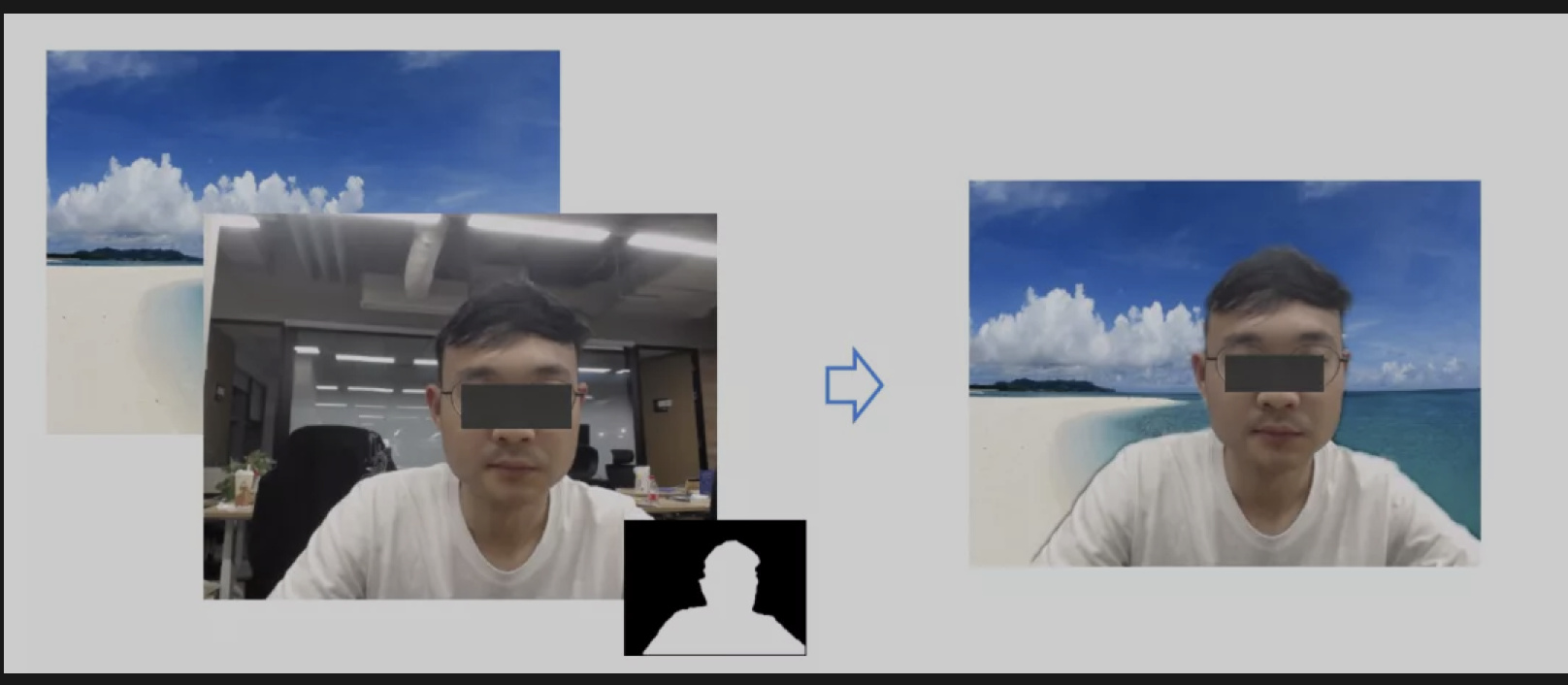
最后,我们在通过人像分割处理后,会通过 WebGL 来实现图像的滤波、抖动消除与画面合成,最后会得到下图的效果。
总结
目前在使用 WebAssembly 的过程中还存在一些痛点。首先在上文提到过,我们会通过 SIMD 指令来优化计算效率。目前 WebAssembly 的 SIMD 指令优化仅支持 128-bit 数据宽度。所以目前社区中也有很多人提出,如果可以实现对 256-bit AVX2 及512-bit AVX512 指令的支持能进一步改善并行运算性能。
第二,目前 WebAssambly 是无法直接访问 GPU 的。如果它能够提供较直接的OpenGL ES 调用能力,则可避免 OpenGL ES 到 WebGL 的 JSBridge 性能开销。
第三,目前 WebAssambly 还无法直接访问音视频数据。从Camera和Mic采集的数据需要经过较多的处理步骤才能到达wasm。
最后,针对 Web 端人像分割,我们总结了几点:
- WebAssembly是Web平台使用机器学习的正确方法之一
- 特定情况下启用SIMD、多线程带来性能提升有显著意义
- 当基本运算性能和算法设计较差时,SIMD、多线程带来的性能提升意义不大
- 使用WebGL进行视频处理和渲染时,WebAssembly输出数据需保持WebGL纹理采样的格式兼容
- 运用WebAssembly进行实时视频处理时需考虑整个Web处理流程中的关键开销,并做合适优化提升整体性能








2023-12-13-175522现在wasm已经支持多线程,通过开启相关特性就已经可以使用
对于SharedBuff,有哪些数据会被拷贝呢
这块源码开放没