


在 Python 中处理音频数据、什么是梅尔声谱图以及如何生成梅尔声谱图?

这是音频深度学习系列文章的第二篇。在上一篇文章中,我们学习了声音是如何被数字化的,知道了我们要把声音转换为声谱图从而在深度学习架构中使用。在本文中,我们将更详细的了解怎么把声音转换为声谱图,以及怎样调整转换来获得更好的性能。
因为数据准备非常重要(在音频深度学习模型中尤为重要),所以它是接下来的两篇文章的重点内容。
下面先列出音频深度学习这个系列的文章概要,我的研究目的是,不仅要理解音频深度学习是怎么工作的,还要理解这样工作的原因。
1.前沿技术(什么是声音?声音是怎么被数字化的?音频深度学习解决了我们日常生活中的哪些问题?什么是声谱图以及它为什么这么重要?)
2.为什么梅尔声谱图性能更佳(本文)(在 Python 中处理音频数据、什么是梅尔声谱图以及如何生成梅尔声谱图?)
3.功能优化和增强(通过超参数调整和数据增强来增强声谱图的功能,从而获得最佳性能)
4.音频分类(对普通声音进行分类的端到端的示例和架构、适用于多种场景的基础应用。)
5.自动语音识别(语音转文本算法和架构、使用 CTC Loss 和解码来对齐序列
6.集束搜索(语音转文本和 NLP 应用中常用的用来增强预测的算法)
音频文件格式和 Python 库
用于深度学习模型的音频数据起初是数字音频文件。无论是听录音或是听音乐,这些文件会有不同的格式,压缩方式不同,格式就也不同。文件格式包括 .wav、.mp3、.wma、.aac、和 .flac 等。
Python 有一些很不错音频处理库,Librosa 就是其中之一,它功能多样,常用的还有 scipy。如果你使用的是 Pytorch,它有一个配套库,叫作 torchaudio,该库与 Pytorch 紧密结合。Pytorch 没有 Librosa 的功能多,但它是专门为深度学习开发的。
这些音频处理库可以读取各种格式的音频文件。
首先要加载文件,比如用 librosa:
import librosa
# Load the audio file
AUDIO_FILE = './audio.wav'
samples, sample_rate = librosa.load(AUDIO_FILE, sr=None)
或者,使用 scipy 执行相同的操作:
from scipy.io import wavfile
sample_rate, samples = wavfile.read(AUDIO_FILE)
然后将声波可视化:
import librosa.display
import matplotlib.pyplot as plt
# x-axis has been converted to time using our sample rate.
# matplotlib plt.plot(y), would output the same figure, but with sample
# number on the x-axis instead of seconds
plt.figure(figsize=(14, 5))
librosa.display.waveplot(samples, sr=sample_rate)
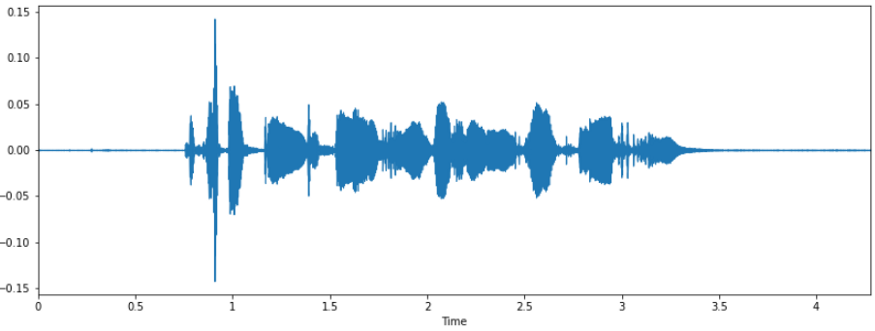
可视化声波(图片来自作者)
听一下这段声音。如果你使用的是 Jupyter 笔记本电脑,可以直接在笔记本的其中一个单元播放音频。
from IPython.display import Audio
Audio(AUDIO_FILE)

在笔记本单元中播放音频(图片来自作者)
音频信号数据
正如我们在上一篇文章中所看到的,获得音频数据要在固定的时间间隔内对声波进行采样,并测试每个样本的声波的强度或振幅。音频的元数据包括采样率,即每秒的采样数。
音频是以压缩格式保存在文件中的,加载完成后,文件会被解压并转换为 Numpy 数组,无论文件的原始格式是什么,最后获得的数组看起来都是一样的。
音频在存储器中表现为数字时间序列,代表着每个 timestep 的振幅。例如,如果采样率为16800,则一秒钟的音频片段就包含 16800 个数字。由于测量是在固定的时间间隔下进行的,因此该数据只包含振幅值,不包含时间值。在给定采样率的情况下,我们可以计算出每个振幅值是在什么特定时间点测量的。
print ('Example shape ', samples.shape, 'Sample rate ', sample_rate, 'Data type', type(samples))
print (samples[22400:22420])

我们可以通过比特位深了解每个样本的振幅测量可以取多少个可能的值 。例如,比特位深为 16 表示振幅值可以在 0 到 65535 (2 ¹⁶ -1)之间。比特位深会影响音频测量的分辨率,比特位深越高,音频保真度越好。
比特位深和采样率决定了音频分辨率(来源)
声谱图
深度学习模型很少将这种原始音频直接输入。正如我们在本系列第一篇文章了解的那样,大部分时候是将音频转换成声谱图。声谱图是声波的“快照”。因为它是图像,所以非常适合输入处理图像的基于 CNN 的架构中。
声谱图是使用 Fourier Transforms 从声音信号中生成的。Fourier Transforms 将信号分解成其组成频率,并显示信号里的每个频率的振幅。
声谱图将声音信号的持续时间缩短为小的时间段,然后将 Fourier Transform 应用于每个时间段来确定该段中所含的频率。然后把所有时间段的 Fourier Transform 合为一个图。
声谱图绘制了频率(Y 轴)与时间(X 轴)的关系,使用不同的颜色表示每个频率的振幅。颜色越亮,信号越强。
sgram = librosa.stft(samples)
librosa.display.specshow(sgram)

简单声谱图(图像来自作者)
但是,我们并没从这个声谱图上看到什么信息。为什么我们从前在科学课上看到的都是彩色声谱图呢?
这是因为人类感知声音的方式比较独特,我们能够听到的大多数声音都集中在狭窄的频率和振幅范围内。所以我们先来探讨一下怎么生成漂亮的声谱图。
人类是怎么感知频率的?
我们把听到的声音频率叫作“音调”,这是对频率的主观印象。因此,高音调的声音比低音调声音的频率更大。人类不会线性感知频率,我们对低频之间的差异比高频更为敏感。
例如,听下面几组声音:
- 100 赫兹和 200 赫兹
- 1000 赫兹和1100 赫兹
- 10000 赫兹和10100 赫兹
你对每组声音的“距离”有什么 看法 ?你能区分每组声音吗?
尽管每对声音之间的实际频率差都在 100 赫兹,但 100 赫兹和 200 赫兹 听起来要 比 1000 赫兹和1100 赫兹听起来 相距更远 。而且,你很难区分 10000 赫兹和 10100 赫兹的区别。
但是,如果我们明白 200 赫兹的频率实际上是100 赫兹的两倍,而 10100 赫兹的频率仅比10000 赫兹的频率高1%,这一切就说得通了。
这就是人类感知频率的方式。我们是通过对数刻度而不是线性刻度来感知频率的。那么,如何用数据说明这一点呢?
梅尔刻度
梅尔刻度的开发就是为了证明这一点,这个刻度是与大量听者进行试验得来的。它是音高的刻度,因此听者认为每个单元与下一个单元的音高距离相等。
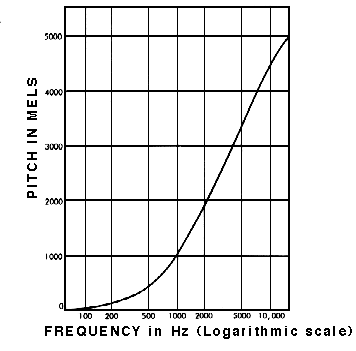
梅尔刻度测量人类对音调的感知 (图片来自 Barry Truax 教授,已获得授权)
人类是怎么感知振幅的?
人类对声音振幅的感知就是声音的响度。与频率相似,我们听到的音量增大,一般都是对数的,不是线性的,我们使用分贝表来解释这个问题。
分贝刻度
在此刻度上,0 分贝表示完全静音,由此网上,测量单位呈指数增长,10 分贝是 0 分贝的 10 倍,20 分贝是100 倍,30 分贝是1000倍,高于100 分贝的声音会让人感到难受。
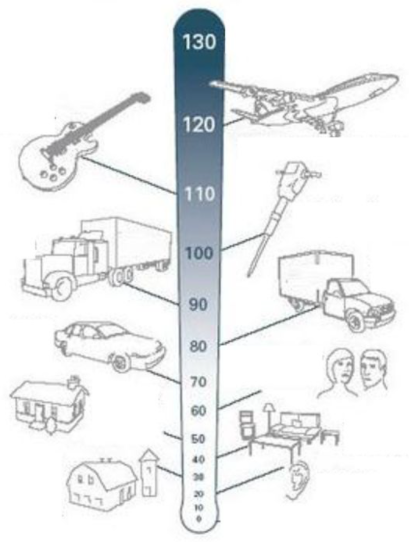
普通声音的分贝等级(图片改编自这里)
所以,为了真实地处理声音,我们在处理数据的频率和幅度时,必须通过梅尔刻度和分贝刻度来使用对数刻度。
这正是梅尔声谱图的作用。
梅尔声谱图
相对于绘制频率与时间的常规声谱图,梅尔声谱图有两个关键不同:
- Y 轴为梅尔刻度而不是频率。
- 使用分贝刻度代替振幅来指示颜色。
深度学习模型通常使用梅尔声谱图而不是简单的声谱图。
我们修改上面的声谱图代码,使用梅尔刻度代替频率。
# use the mel-scale instead of raw frequency
sgram_mag, _ = librosa.magphase(sgram)
mel_scale_sgram = librosa.feature.melspectrogram(S=sgram_mag, sr=sample_rate)
librosa.display.specshow(mel_scale_sgram)
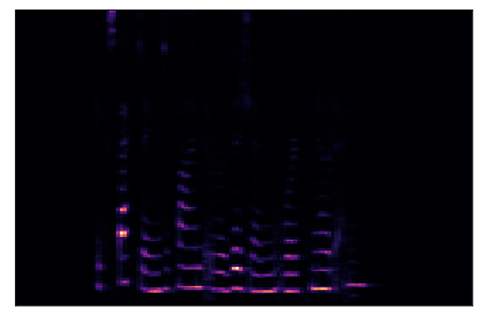
使用梅尔刻度的声谱图(图片来自作者)
这个图片就比之前得到的图片的效果好一些,但是大多数声谱图仍然很暗,没有提供足够的有用信息。因此,我们要修改它,使用分贝刻度来代替振幅。
# use the decibel scale to get the final Mel Spectrogram
mel_sgram = librosa.amplitude_to_db(mel_scale_sgram, ref=np.min)
librosa.display.specshow(mel_sgram, sr=sample_rate, x_axis='time', y_axis='mel')
plt.colorbar(format='%+2.0f dB')
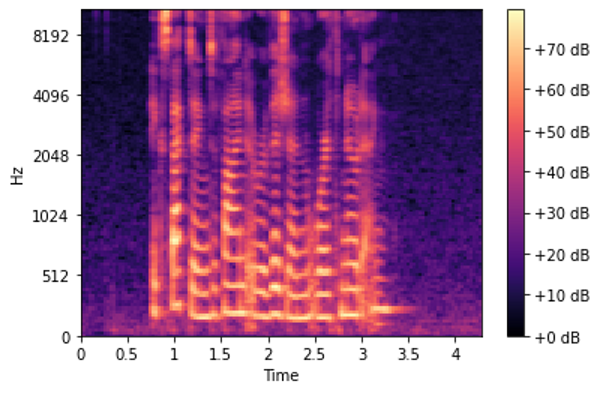
梅尔声谱图(图片来自作者)
大功告成啦! ![]()
![]()
![]() 这才是我们真正想要的东西~~~
这才是我们真正想要的东西~~~
总结
我们已经知道了怎么对音频数据进行预处理并准备梅尔声谱图,但是在将它们输入到深度学习模型之前,我们必须对其进行优化从而获得最佳性能。
在我的下一篇关于音频深度学习文章里,我将探讨如何通过调整梅尔声谱图来增强我们的模型数据,以及增强音频数据从而让我们模型输入内容更广泛。
原文作者 Ketan Doshi
原文链接https://towardsdatascience.com/audio-deep-learning-made-simple-part-2-why-mel-spectrograms-perform-better-aad889a93505





{kind=link}
{kind=link}