这是一篇关于深度学习音频应用和架构的指南,读了本文,你就会明白为什么要了解声谱图。

图片来自 Unsplash(原发布者:Jason Rosewell)
作为深度学习发展最迅速、最具前景的两大分支,计算机视觉和 NLP 应用已经获得了广泛关注,但实际上音频数据的深度学习方面还有很多具有开创意义的用例,还没有获得足够关注。所以,我打算以此为主题写一系列相关文章,深入探讨音频深度学习。
下面先列出这个系列的文章概要,我的研究目的是,不仅要理解音频深度学习是怎么工作的,还要理解这样工作的原因。
1.前沿技术(本文)(什么是声音?声音是如何被数字化的?音频深度学习解决了我们日常生活中的哪些问题?什么是声谱图以及它为什么这么重要?)
2.为什么梅尔声谱图性能更佳(在 Python 中处理音频数据、什么是梅尔声谱图以及如何生成梅尔声谱图?)
3.功能优化和增强(通过超参数调整和数据增强来增强声谱图的功能,从而获得最佳性能)
4.音频分类(对普通声音进行分类的端到端的示例和架构、适用于多种场景的基础应用。)
5.自动语音识别(语音转文本算法和架构、使用 CTC Loss 和解码来对齐序列)
6.集束搜索(语音转文本和 NLP 应用中常用的用来增强预测的算法)
因为很多人对这个领域还非常陌生,所以本文作为本系列文章的第一篇,我会先就本话题进行一个简介,并音频应用的深度学习情况进行概述。 读了我的这篇文章,大家会了解什么是音频,以及它是如何以数字形式表示的。另外,我还会探讨音频应用对我们日常生活的广泛影响,以及这些音频应用使用的架构和模型技术。
什么是声音?
相信大家在课本里都学过,声音信号是由空气压力的变化而产生的。 我们可以测量压力变化的强度,并绘制这些测量值随时间的变化。
声音信号经常在规律的、固定的区间内重复,因此每个波都具有相同形状。下图的高度表示声音的强度,我们称之为振幅。
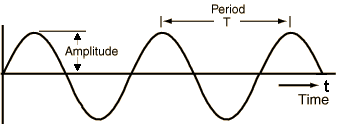
显示振幅与时间的简单重复信号(图片来自马克-利伯曼教授,已获得授权)
信号完成一个完整波所花费的时间为周期,信号在一秒钟内发出的波数为频率。 频率是周期的倒数,频率的单位是赫兹。
生活中的大多数声音可能并不遵循这种简单而有规律的周期模式。不同频率的信号可以添加在一起,形成一种具有更复杂的重复模式的复合信号。我们听到的所有声音,包括人声,都由这样的波形组成。 例如,下图可能是一种乐器的声音。

具有复杂重复信号的音乐波形 (图片来自乔治-吉布森教授,已获得授权)
人耳能根据声音的“质量”(也称为音色)来区分不同的声音。
我们怎么以数字表示声音?
为了把声波数字化,我们必须将信号转换为一系列数字,以便将其输入到模型中。 我们每隔相同的时间段对声音的振幅进行测量,然后把信号转换为数字。
每隔相同的时间段进行的抽样测量
每一次这样的测量就是一个样本,采样率是每秒的样本数。 例如,采样率通常约为每秒 44,100 个样本,也就是说一个 10 秒的音乐片段有 441,000 个样本!
为深度学习模型准备音频数据
在深度学习尚未出现的几年前,计算机视觉的机器学习应用都是依靠传统的图像处理技术来做特色工程。 例如,我们会使用算法生成手工制作的特征来检测拐角、边缘和人脸。 在 NLP 应用中,我们也会使用诸如提取 N-gram 和计算术语频率之类的技术。
同样地,音频机器学习应用过去也依赖传统的数字信号处理技术来提取相关特征。 例如,为了理解人类语音,可以使用语音概念来分析音频信号,从而提取音素等元素。 所有这些都需要大量特定领域的专业知识才能解决问题,才能调整系统从而获得更好的性能。
但随着近年来深度学习越来越普遍,它在处理音频方面也取得了巨大的成功。有了深度学习,传统的音频处理技术就不再需要了,我们可以依靠标准的数据准备来完成,不再需要大量的手动和自定义生成的特征。
而且,我们使用深度学习时实际上并没有处理原始格式的音频数据。我们常常是把音频数据转换为图像,然后使用标准的 CNN 架构来处理这些图像!我们通常会从音频中生成声谱图。所以现在我们首先了解一下什么是频谱图,然后使用频谱图来理解声谱图。
频谱图
正如上文所说,我们可以把不同频率的信号加在一起来形成复合信号,这些复合信号代表真实发生的声音,所以,如果一个信号由多种不同频率组成,我们可以称它为这些频率的总和。
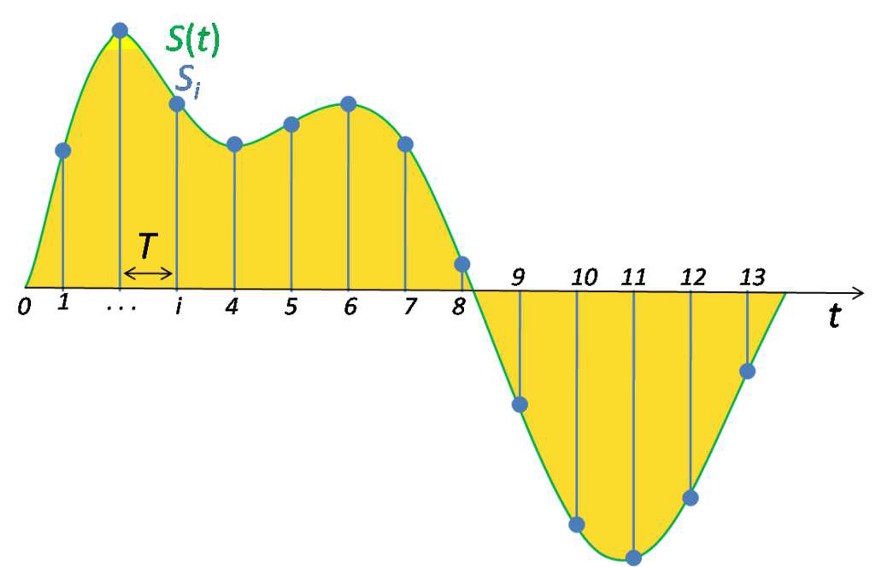
频谱图是组合在一起产生信号的一组频率,例如,下图显示了一段音乐的频谱。
频谱图绘制了信号中的所有频率以及每个频率的强度或振幅。
频谱图:显示构成声音信号的多个频率 (图片来自 Barry Truax 教授,已获得授权)
信号中的最低频率叫作基频,基频的整数倍的频率叫作谐波。
例如,如果基频为 200 赫兹,则它的谐波频率为 400 赫兹、600 赫兹,以此类推。
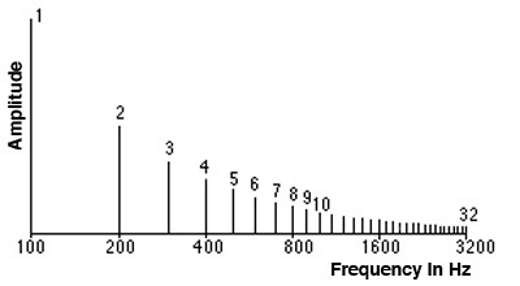
时域与频域
我们前面看到的显示幅度与时间的波形是表示声音信号的一种方式。 由于 X 轴显示的是信号的时间值范围,因此我们是在时域中查看信号。
频谱是表示相同信号的另一种方式。 它显示了振幅与频率之间的关系,并且由于 X 轴显示了信号的频率值的范围, 因此在某个时刻 ,我们是在频域中查看信号。
时域和频域
声谱图
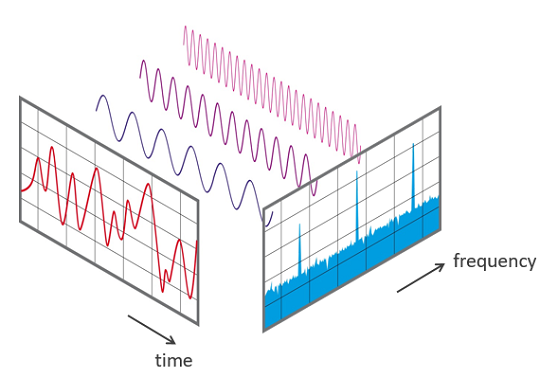
由于信号随时间变化会产生不同的声音,因此其组成频率也会随时间而变化。 换句话说,它的频谱是随时间变化的。
信号的声谱图绘制了它频谱随时间的变化,就像信号的“照片”一样。它在 X 轴上绘制时间,在 Y 轴上绘制频率,就好像我们在不同的时间点一次又一次地拍摄频谱,然后将它们全部合并为一个图。
它使用不同的颜色表示每个频率的振幅或强度。颜色越亮,信号越好。频谱图的每个垂直“切片”本质上是信号在该时间点的频谱,显示了在该时间点信号中发现的每个频率中的信号强度是如何分布的。
在下面的示例中,第一张图片显示是时域中的信号,即振幅与时间。 我们可以从图中看出来一个片段在每个时间点的音量,但是没有告诉我们存在哪些频率。
声音信号和声谱图 (图片来自作者)
第二张图片是声谱图,它显示了频域中的信号。
生成声谱图
声谱图是利用傅立叶变换将信号分解成其组成频率而产生的。如果你已经忘记了大学时学习的傅立叶转换,不用担心![]() !我们不需要回忆所有的数学知识,只需要使用简洁好用的 Python 库函数就可以一步生成声谱图,具体怎么操作可以看下篇文章哦~
!我们不需要回忆所有的数学知识,只需要使用简洁好用的 Python 库函数就可以一步生成声谱图,具体怎么操作可以看下篇文章哦~
音频深度学习模型
现在,我们了解了什么是声谱图,它是音频信号的等价紧凑表示,就像是信号的“指纹”,是音频数据的基本特征捕获并转换为图像的一个好方法。
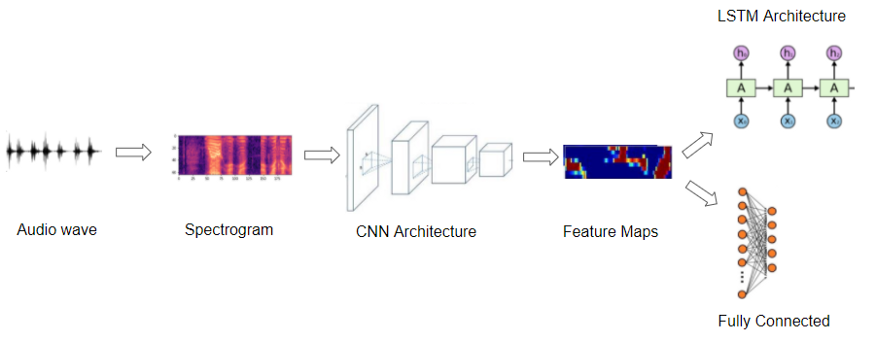
音频深度学习模型使用的典型管道(图片来自作者)
因此,大多数深度学习音频应用都使用声谱图来表示音频,他们通常采用以下步骤:
- 首先,获取波形文件形式的原始音频数据。
- 然后,将音频数据转换为其对应的声谱图。
- (可选)使用简单的音频处理技术来增强声谱图数据。 (在转换声谱图之前,也可以对原始音频数据进行一些增强或清除)
- 现在我们有图像数据,我们可以用标准的 CNN 架构来处理它们,并提取特征图,这是声谱图像的编码表示。
下一步是根据你要解决的问题,从这个编码表示中生成输出预测。
- 例如,对于音频分类问题,我们可以将音频传入分类器,分类器通常由一些完全连接的线性层组成。
- 对于语音转文本问题,我们可以将其传递给一些 RNN 层来从这个编码表示中提取文本句子。
当然,我们跳过了许多细节,也进行了一些广义的概括,因为本文探讨的是较高层次的问题。 在本系列后续的文章中,我们会详细介绍相关步骤以及使用的架构。
音频深度学习解决了哪些问题?
日常生活中的音频数据各式各样,例如,人类语音、音乐、动物声音和其他自然声音,还有人类活动带来的人造声音,例如,汽车和机械。
我们的生活中到处都是各种各样的声音,所以会有很多需要我们处理和分析音频的场景。现在深度学习已经非常成熟,我们可以用深度学习解决一些用例。
音频分类
音频分类是最常见的用例之一,它涉及获取声音并将其分为几个类别。 例如,识别声音的类型或来源, 声音是汽车的起步声?锤子的声音?口哨声?还是狗叫声?
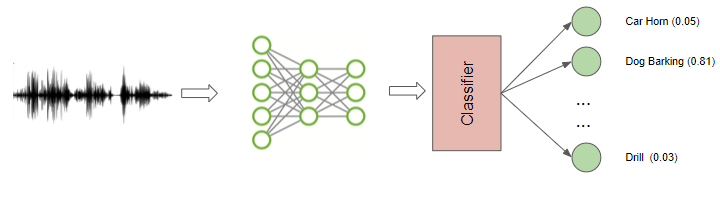
普通声音的分类 (图片来自作者)
显而易见的是,音频分类的应用市场是巨大的。我们可以根据机器或设备发出的声音来检测故障,或把它应用于监控系统来检测安全漏洞。
音频分离与分割
音频分离是指将感兴趣的信号从混合信号中分离出来,以便进一步处理。 例如,你希望将个人声音与背景噪音区分开,或者将小提琴的声音与音乐表演的其余部分区分开。
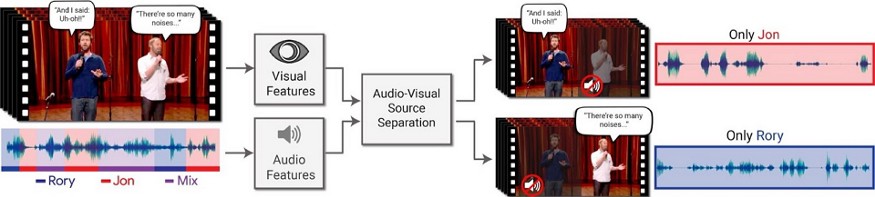
从视频中分离出某个说话人( 图片来自Ariel Ephrat,已获得授权)
音频分段被用于对音频流中的特定部分进行突出显示,例如,它可以用于医疗诊断,以检测患者的心跳并发现异常。
音乐流派分类和标记
现在,音乐推流服务广受欢迎,我们都知道可以基于音频来识别和分类音乐,深度学习可以分析音乐的内容并找出音乐所属流派。 这是一个多标签分类问题,因为一个音乐有可能属于多个流派,例如该音乐可能会被划分进摇滚、流行、爵士、萨尔萨舞、器乐等流派,也可能被划分进“老歌”、“女歌手”、“快乐”、“派对音乐”的分类里。
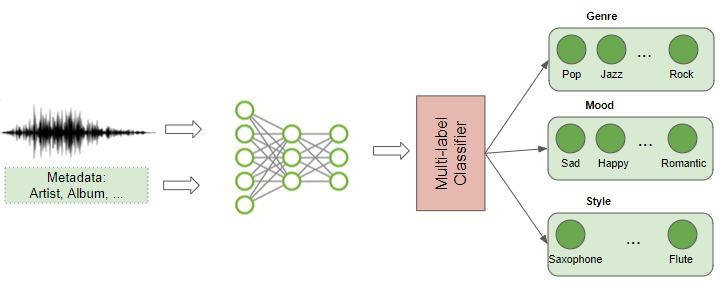
音乐流派分类和标签 (图片来自作者)
当然,除了音频本身,还有关于音乐的元数据,例如歌手、发行日期、作曲家、歌词等,我们可以用这些元数据为音乐添加多个标签。
音乐流派分类和标记可以根据音频特点为音乐收藏建立索引,也可以根据用户的喜好向用户推荐音乐,还可以搜索和检索与用户正在听的歌曲相似的歌曲。
音乐生成和转录
很多新闻都提到深度学习可以用编程方式生成仿真人脸和图片,还能编写语法正确的智能信件或新闻报道。
音乐一代 (图片来自作者)
同样道理,我们可以用深度学习生成与特定流派、乐器甚至特定作曲家风格类似的合成音乐。
“音乐转录”则反向应用了此功能。 它采用一些声学知识并对其进行注释,来创建音乐中的音符乐谱。
语音识别
从技术上讲,语音识别也是一个音频分类问题,但涉及到口语识别。我们可以用它识别说话者的性别或姓名(例如,这是比尔·盖茨或汤姆·汉克斯?是科坦的声音还是入侵者的声音?)
语音识别:探测入侵者 (图片来自作者)
我们有可能想检测人类情感,从他们的声音语调中识别其情绪,例如这个人是快乐、悲伤、愤怒还是焦虑的?
我们还可以用它检测动物的声音,识别是什么动物在发出声音,或者识别这个动物是是温柔的、刺耳的、威胁的还是惊恐的叫声。
语音转文本和文本转语音
我们可以更好的处理人类语音,不仅可以识别说话者,还能理解他们说的内容。 这涉及从音频中提取词汇,并将词汇转录为文本语句。
这是最具挑战性的应用之一,因为它不仅涉及音频分析,还涉及 NLP,并且还需要开发一些基本的语言功能,才能从话语中辨别出不同的单词。
语音转文字 (图片来自作者)
反之,我们可以通过语音合成走向另一个方向,我们可以把书面文本转换成语音,例如,使用人工语音作为会话代理。
可以理解人类语言就决定了它可以用于我们工作生活的很多应用,如语音聊天室等,当然,一切还都是摸索中,路漫漫其修远兮~
目前广泛应用的是例如 Alexa、Siri、sCortana 和 Google Home 等虚拟助手,这些都是围绕此功能研发的用户友好型产品。
结论
我们在一个相对较高的层次上,探讨了音频应用的广度,并介绍了解决这些问题的一般技术。
下一篇文章我们将更多地关注音频数据预处理和生成声谱图的技术细节,我们还会探讨用于调整性能的超参数。
在此基础上,我们会深入研究一些端到端的示例,从普通声音的分类开始,最后是较具挑战性的自动语音识别,我们还会介绍 CTC 算法。
如果你喜欢这篇文章, 你一定也会喜欢我这个系列的其他文章哦,欢迎大家的阅读和反馈 ![]()
![]()
![]() ~
~
原文作者 Ketan Doshi
原文链接https://towardsdatascience.com/audio-deep-learning-made-simple-part-1-state-of-the-art-techniques-da1d3dff2504