用语音识别将音视频转换为文本,添加GUI并使用线程来提高性能

图片来自Pexels的Anna Shvets
我偶尔需要访谈很多转录研究项目的参与者,这类项目的拨款通常会包括转录费用。目前,人类转录仍是这类工作的黄金标准。当然,你也可以自己转录你的访谈,但这可能是一项非常耗时和费力的工作。一些定性研究者也认为,要想更加熟悉数据,可以先从转录自己的访谈开始。
有很多适用于这项任务的软件,其中包括免费试用和各种定价模式的软件。用Python创建一个脚本来做也很简单。要对网上几个较长的采访(每个>1小时)进行转录,我决定创建一个带有图形界面的简单程序来管理整个过程。本文描述并实操了单一脚本的基本概念,展示了如何添加图形用户界面(GUI)并使用线程来提高性能。
假定读者有使用Python的经验,并且熟悉面向对象编程(OOP)等概念。本例使用的是Python 3.x和PyQt5。
工作实例
我们需要3个模块, 语音识别 、 wave 和 moviepy, 这些都可以用标准方法pip安装。
pip install Wave
pip install moviepy
pip install SpeechRecognition
然后它们可以和其他所需的模块一起被导入到Python文件中:
import wave, math, contextlib
import speech_recognition as sr
from moviepy.editor import AudioFileClip
现在,我们将要导入的mp4音视频文件和将视频转换为音频时所创建的音频文件进行硬编码。
transcribed_audio_file_name = "transcribed_speech.wav"
zoom_video_file_name = "zoom_0.mp4"
接下来,我们要使用 moviepy.editor 中的 AudioFileClip 类将视频转换为音频。这将把视频转换为音频,特别是转换成一个wav文件。
audioclip = AudioFileClip(zoom_video_file_name)
audioclip.write_audiofile(transcribed_audio_file_name)
下一步是将这个音频文件转换为文本。这里的难点在于,发送至API的单个请求有10MB左右的限制,这意味着我们需要分段转录音频。要做到这一点,首先要知道音频文件的持续时间,这样我们才能把它分成可管理的小块。
contextlib.closing 与 with 语句一起工作,在代码块进入和退出时通知内容管理器。这里,我们使用wave库打开wav文件,并获得帧数和可以用来计算文件持续时间的帧速率。
with contextlib.closing(wave.open(transcribed_audio_file_name,'r')) as f:
frames = f.getnframes()
rate = f.getframerate()
duration = frames / float(rate)
现在可以把它分成一些合适的数字,用于分块转录文件。在本例中,我们用了60秒。
total_duration = math.ceil(duration / 60)
接下来,我们要创建一个语言识别器的实例。
r = sr.Recognizer()
最后,我们就能将音频转换为文本了。记录函数可使用一个持续时间(单位:秒)。在with语句中,后续的记录行将接着上一次的记录。这里我们使用一个偏移量来捕捉下一个60秒的片段,并将转录的文本写到一个文本文件中。我们使用recognition_google来识别语音。还有一些替代方法, 如recognize_bing()、recognize_wit()和recognize_google_cloud() 。将转录的文本写到一个文本文件中,添加一个额外的空格,这样后面的句子之间就有了空格。
for i in range(0, total_duration):
with sr.AudioFile(transcribed_audio_file_name) as source:
audio = r.record(source, offset=i*60, duration=60)
f = open("transcription.txt", "a")
f.write(r.recognize_google(audio))
f.write(" ")
f.close()
完整的脚本如下所示:
import wave, math, contextlib
import speech_recognition as sr
from moviepy.editor import AudioFileClip
transcribed_audio_file_name = "transcribed_speech.wav"
zoom_video_file_name = "zoom_0.mp4"
audioclip = AudioFileClip(zoom_video_file_name)
audioclip.write_audiofile(transcribed_audio_file_name)
with contextlib.closing(wave.open(transcribed_audio_file_name,'r')) as f:
frames = f.getnframes()
rate = f.getframerate()
duration = frames / float(rate)
total_duration = math.ceil(duration / 60)
r = sr.Recognizer()
for i in range(0, total_duration):
with sr.AudioFile(transcribed_audio_file_name) as source:
audio = r.record(source, offset=i*60, duration=60)
f = open("transcription.txt", "a")
f.write(r.recognize_google(audio))
f.write(" ")
f.close()
添加一个图形用户界面(GUI)。
这里可以用基本的脚本,但如果我们能添加一个图形用户界面,效果会更好。这可以帮助定位文件,并增加一些功能,如进度条来监测大型转录的进度。我们还可以在屏幕上而不是控制台的文本框中显示转录的文本。大多数情况下,我使用像Flask这样的网络框架来构建前端,并使用HTML、CSS添加GUI元素,所以这是我第一次试着在Python中制作一个非基于网络的GUI。在对工具的选择做了一番研究后,我发现了 PyQt 。Qt是一个跨平台的框架(用C++编写),它为创建GUI提供了一个开源的工具箱。
最新的版本是PyQt5,它提供了一套对生成GUI非常有用的库,以下是用pip安装的方法:
pip install PyQt5
与Qt相关的另一个很有用的工具是用于Windows或Mac的QT Designer工具(可以从以下网站下载:https://build-system.fman.io/qt-designer-download)。它允许人们将常见的用户界面(UI)元素拖放到一个窗口上,从而生成一个前端。以下图片显示了为转录程序生成的简单前端:
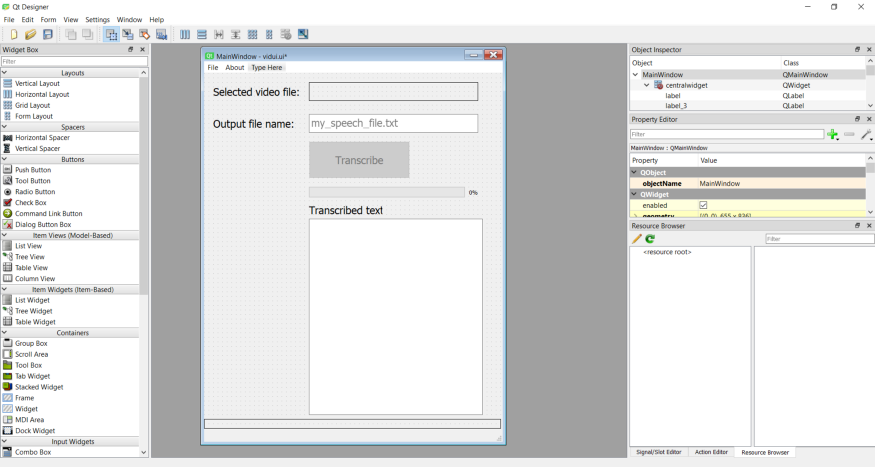
使用Qt Designer设计的GUI屏幕截图(图片由作者提供)。
这里我们有一个简洁的菜单,其中的 "文件 "包含 "打开mp4视频记录 "和 “新建”。我们也有一个 "关于 "选项,即 “关于vid2text”。主窗口上有一个标签,显示用户选择的视频文件。用户可以在下面的方框中输入一个文件名,以便将转录内容写入其中。接下来我们有一个转录按钮,在选择视频文件之前,这个按钮默认是禁用的。在这个按钮下有一个进度条,用来更新用户当前的转录进度。随后是一个文本框,用于显示转录的文本。最后,在屏幕的底部有一个标签,为用户显示各种信息。
一旦使用设计器直观地创建了前端,我们就可以把文件保存为* .ui 文件。使用命令行(例如终端或 Anaconda 提示符),我们可以运行以下命令,从 ui 文件中生成 Python 代码。
pyuic –x vidui.ui –o vid2speechapp.py
当我们运行以下代码时,它会为我们用 QT 设计器设计的GUI产生Python代码,如下图所示。 -o 写输出生成文件, -x 生成额外的代码来测试这个类。




self.actionOpen_mp4_video_recording.triggered.connect(self.open_audio_file)
如果我们运行 Python 文件,它将启动一个窗口,这个窗口看起来就像我们创建的用户界面。除了生成各种UI组件外,没有其他功能,我们需要自己添加。为了从先前的脚本中添加功能,我们可以从菜单项开始,点击菜单连接到一个类方法。这里我们用触发器. connect() 写出我们想调用的方法的名称(即 self.open_audio_file ),不加括号(圆括号)。
self.actionOpen_mp4_video_recording.triggered.connect(self.open_audio_file)
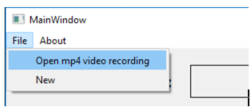
菜单选项的屏幕截图(图片由作者提供)
如果我们能打开一个文件对话框,让用户选择一个文件来工作,效果会更好。为了实现一个文件对话框,我们可以使用 QFileDialog ,前提是要把它从 PyQt5 QtWidgets 中导出来。
from PyQt5.QtWidgets import QFileDialog
相对应的方法是使用QFileDialog来启动一个文件对话框,以便用户可以选择所需的音视频文件。选择的文件名和路径可以存储在file_name变量中。这会返回一个第一个元素包含文件名/路径的元组。我们可以检查它是否以mp4为后缀,如果是,我们就可以启用转录按钮。接下来,我们可以在self.mp4_file_name变量中存储文件名,还可以清除信息标签,以防它包含以前的错误信息。最后,我们就可以更新标签以显示所选的文件。如果文件不是以mp4结尾,我们可以向用户显示一个提示的信息,要求他们选择一个mp4文件。
def open_audio_file(self):
"""Open the audio (*.mp4) file."""
file_name = QFileDialog.getOpenFileName()
if file_name[0][-3:] == "mp4":
self.transcribe_button.setEnabled(True)
self.mp4_file_name = file_name[0]
self.message_label.setText("")
self.selected_video_label.setText(file_name[0])
else:
self.message_label.setText("Please select an *.mp4 file")
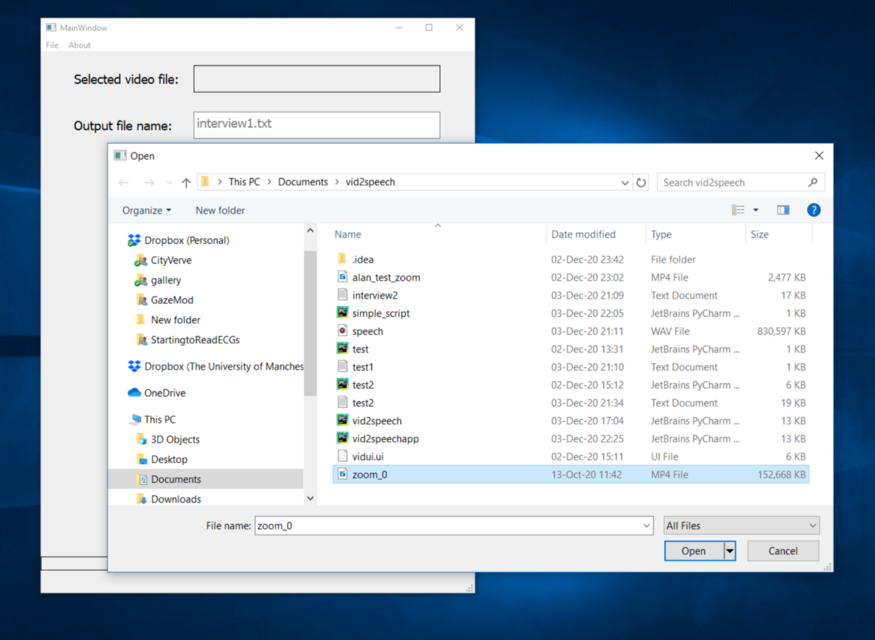
显示用户选择mp4文件的图片(图片由作者提供)
接下来,我们可以创建一个方法链接来开始转录。为此,我们可以使用 clicked.connect 并传入我们想要调用的方法,本例中传入的方法是 process_and_transcribe_audio 。
self.transcribe_button.clicked.connect(self.process_and_transcribe_audio)
这个方法禁用了转录按钮,所以在转录完成之前按钮不能用。然后它又调用了两个方法,一个是将视频转换为音频,另一个是转录文本。
def process_and_transcribe_audio(self):
"""Process the audio into a textual transcription."""
self.transcribe_button.setEnabled(False)
self.convert_mp4_to_wav()
self.transcribe_audio(self.audio_file)
首先,我们需要从 moviepy 导入 AudioFileClip 类。
from moviepy.editor import AudioFileClip
接下来,我们可以给这个类添加一个初始化方法。在这里,我们可以设置一些变量来存储mp4文件名、输出文件和我们将转换为音视频文件的音频(wav)文件名。
def __init__(self):
"""Initialisation function."""
self.mp4_file_name = ""
self.output_file = ""
self.audio_file = "speech.wav"
转换方法和以前一样,并为转录产生 语音.wav 音频文件。
def convert_mp4_to_wav(self):
"""Convert the mp4 video file into an audio file."""
audio_clip = AudioFileClip(self.mp4_file_name)
audio_clip.write_audiofile(self.audio_file)
一旦转换为音频格式,我们就可以开始转录了。这里我们从文本中获得文件名,这个文本是用户在输出文件名文本框中输入的。

输出文件名文本框的屏幕截图(图片由作者提供)
我们使用toPlainText()法从文本框中获取文本。如果他们没有输入任何东西,可以使用默认名称 “my_speech_file.txt”。我们通过寻找输入的文本长度来对此进行验证,这个长度应该大于0。核心转录代码和以前一样。在这之后,我们将进度条设置为100%,重新启用转录按钮并清除消息标签中的消息。
def transcribe_audio(self, audio_file):
"""Transcribe the audio file."""
r = sr.Recognizer()
total_duration = self.get_audio_duration(audio_file) / 10
total_duration = math.ceil(total_duration)
if len(self.output_file_name.toPlainText()) > 0:
self.output_file = self.output_file_name.toPlainText()
else:
self.output_file = "my_speech_file.txt"
for i in range(0, total_duration):
with sr.AudioFile(audio_file) as source:
audio = r.record(source, offset=i*10, duration=10)
self.progress_bar.setValue(i)
f = open(self.output_file, "a")
f.write(r.recognize_google(audio))
f.write(" ")
f.close()
self.progress_bar.setValue(100)
self.transcribe_button.setEnabled(True)
self.message_label.setText("")
self.update_text_output()
我们还创建了一个方法来确定音频文件的长度(self.get_audio_duration),方法和以前一样,以及另一个方法来更新进度条的值。
当我们运行这些代码时,GUI停止运行了了,并显示 “没有反应”。我们不能关闭App,也不能以任何方式与它互动。直到任务完成,进度条都没有更新。
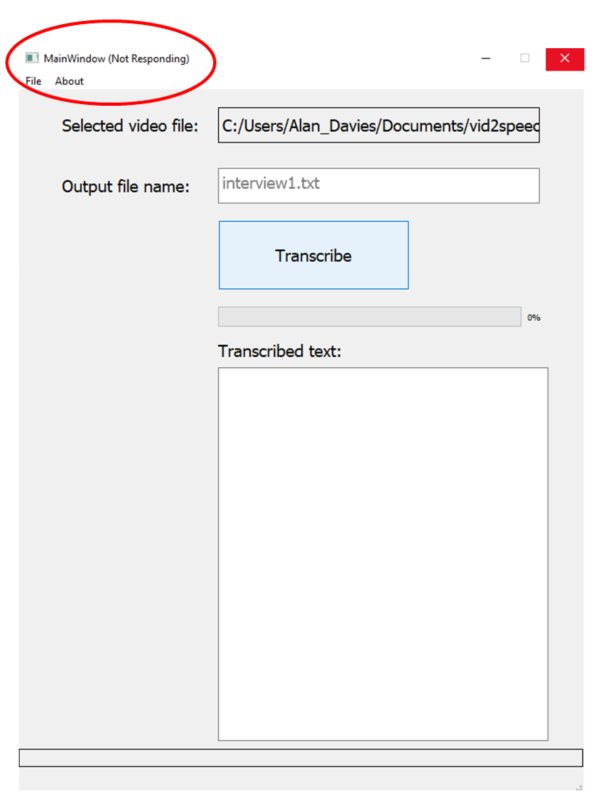
在完成转录之前,应用程序无反应的截图(图片由作者提供)
这在时间较长的录音(一小时以上)中尤其明显。显然,这不是个好迹象,并且产生了十分糟糕的用户体验。要想解决这个问题,将这些任务作为后台任务运行不失为一种方法。
使用线程
为了克服这个问题,我们可以使用线程。线程(执行的线程)让我们能同时运行任务,因此,与其锁定GUI直到完成,不如在后台运行这个任务。这里我们使用QThreads,这些线程的功能或多或少与Python线程相似,但与Qt的匹配度更高。
在这个应用程序中,有两个过程会占用一些时间。第一个是视频到音频的转换;第二个是转录本身。我们可以为这两个过程使用线程,以提高性能。
让我们从一个用于视频到音频转换的线程开始。这里我们使用QThread创建了一个新的类,叫做 convertVideoToAudioThread 。我们可以在初始化函数 init 中传递任何我们需要交互的变量,在这里是mp4文件名和音频输出文件名。
class convertVideoToAudioThread(QThread):
"""Thread to convert mp4 video file to wav file."""
def __init__(self, mp4_file_name, audio_file):
"""Initialization function."""
QThread.__init__(self)
self.mp4_file_name = mp4_file_name
self.audio_file = audio_file
然后我们可以把视频到音频的主要转换代码放在一个运行方法中。
def run(self):
"""Run video conversion task."""
audio_clip = AudioFileClip(self.mp4_file_name)
audio_clip.write_audiofile(self.audio_file)
注意,在使用线程时,我们必能直接调用运行方法,而是要通过使用线程 start() 方法来运行。最后,我们可以添加一个类的析构器,使用 wait() 方法来阻塞线程。当一个对象被垃圾回收时,会调用del方法。
def __del__(self):
"""Destructor."""
self.wait()
然后我们可以更新 convert_mp4_to_wav 方法来使用这个线程。这里,我们还添加了一些消息,为用户更新应用程序的运行。然后我们创建一个名为 convert_thread 的线程,并创建一个 convertVideoToAudioThread 的实例,输入mp4和音频文件名。为了启动该线程,我们使用 start() 方法,该方法将执行run方法。最后,当线程完成时,我们可以使用 finished.connect() 法来调用另一个方法。这里我们用它来调用我们的 finally_converting() 方法。
def convert_mp4_to_wav(self):
"""Convert the mp4 video file into an audio file."""
self.message_label.setText("Converting mp4 to audio (*.wav)...")
self.convert_thread = convertVideoToAudioThread(self.mp4_file_name, self.audio_file)
self.convert_thread.finished.connect(self.finished_converting)
self.convert_thread.start()
完成的转换法会向用户显示一个转换完成的消息,然后运行transcribe_audio()方法。我们将为主要的转录工作创建一个线程。
def finished_converting(self):
"""Reset message text when conversion is finished."""
self.message_label.setText("Transcribing file...")
self.transcribe_audio(self.audio_file)
我们创建一个transcriptionThread类来处理转录问题。它的工作方式与最初的线程大致相同,但还有其他功能。

我们还添加了一个try、except。这是因为如果语音识别器由于一些背景噪音而不能识别输入,它将产生一个UnknownValueError,这会造成终止程序。而change_value = pyqtSignal(int) 是用来在线程运行时发出信号(一个整数),我们可以用它来更新进度条,运行方法中的一行如下所示:
self.change_value.emit(i)
这就发出了for循环计数器的值。这个值的变化被线程的change_value方法所接收,该方法反过来调用set_progress_value方法。
self.thread.change_value.connect(self.set_progress_value)
def set_progress_value(self, val):
"""Update progress bar value."""
increment = int(math.floor(100*(float(val)/self.td)))
self.progress_bar.setValue(increment)
然后我们可以 修改transcribe_audio 函数,以使用新的线程。
def transcribe_audio(self, audio_file):
"""Transcribe the audio file."""
total_duration = self.get_audio_duration(audio_file) / 10
total_duration = math.ceil(total_duration)
self.td = total_duration
if len(self.output_file_name.toPlainText()) > 0:
self.output_file = self.output_file_name.toPlainText()
else:
self.output_file = "my_speech_file.txt"
self.thread = transcriptionThread(total_duration, audio_file, self.output_file)
self.thread.finished.connect(self.finished_transcribing)
self.thread.change_value.connect(self.set_progress_value)
self.thread.start()
以下图片显示了最终版本,进度条更新显示转录进度。完成后,我们将文本文件的内容加载到文本区,如有必要,它会自动添加滚动条。
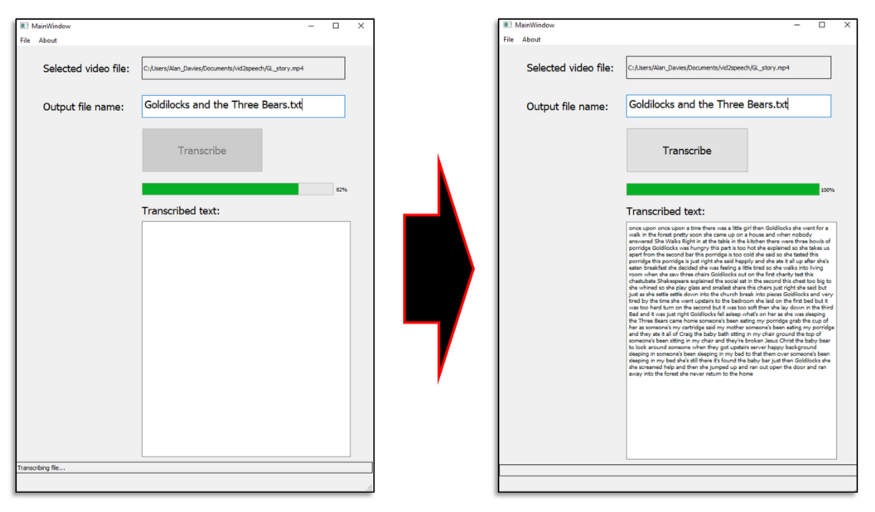
运行中的转录截图(图片由作者提供)
最后,我们可以为新的、关于菜单选项添加功能。新功能只是简单地清除文本字段,并重新设置进度条。关于选项利用 QMessageBox 来显示作者的详细信息。我们可以设置文本、标题和一个图标,在本例中是一个信息图标。
def show_about(self):
"""Show about message box."""
msg = QMessageBox()
msg.setWindowTitle("About vid2speech")
msg.setText(" Created by Dr. Alan Davies,\n Senior Lecturer,\n Health Data Science,\n Manchester University, UK")
msg.setIcon(QMessageBox.Information)
msg.exec_()
其输出结果具体如下:
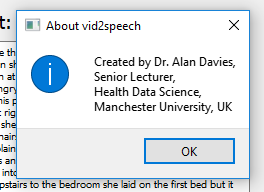
使用QMessageBox显示有关信息的弹出窗口(图片由作者提供)
The final code can be seen here:
最终版本如下所示:











这个应用程序提供了非常基础的例子,功能也不多,因此可以在很多方面上进行改进,比如提供一个加载mp4或wav文件的选项、能选择不同的语音识别器和显示额外的信息,如文件大小/时间。简单的应用程序可以通过图形用户界面来改进,在PyQt和QT Designer等工具中添加这些很容易,我们还可以用线程来克服性能问题,使计算成本高的任务在后台运行,以免影响用户体验。
原文作者 Alan Davies
原文链接 https://towardsdatascience.com/transcribing-interview-data-from-video-to-text-with-python-5cdb6689eea1