增强声谱图功能、实现最佳性能、数据增强

图片来自Unsplash (原发布者:Vidar Nordli-Mathisen)
本文是音频深度学习系列的第三篇文章。通过前面的两篇文章,大家已经了解了:
-
声音是如何数字化的。
-
深度学习架构通常使用声音的声谱图。
-
如何在 Python 中预处理音频数据来生成梅尔声谱图。
本文会通过调整超参数来增强梅尔声谱图的性能,了解音频数据的增强技术,两者都是数据准备的关键,对提高音频深度学习模型的性能非常重要。
下面是音频深度学习系列的文章概要,我的研究目的是,不仅要理解音频深度学习是怎么工作的,还要理解这样工作的原因。
1.前沿技术(什么是声音?声音是如何被数字化的?音频深度学习解决了我们日常生活中的哪些问题?什么是声谱图以及它为什么这么重要?)
2.为什么梅尔声谱图性能更佳(在 Python 中处理音频数据、什么是梅尔声谱图以及如何生成梅尔声谱图?)
3.数据准备和增强(本文)(通过超参数调整和数据增强来增强声谱图的功能,从而获得最佳性能)
4.音频分类(对普通声音进行分类的端到端的示例和架构、适用于多种场景的基础应用。)
5.自动语音识别(语音转文本算法和架构、使用 CTC Loss 和解码来对齐序列)
6.集束搜索(语音转文本和 NLP 应用中常用的用来增强预测的算法)
调整超参数来实现声谱图优化
在音频深度学习(第二部分),我们了解了什么是梅尔声谱图,以及如何使用一些便利的库函数创建声谱图。但是,要让深度学习模型获得其最佳性能,我们应该有针对性地对梅尔声谱图进行优化。
我们可以用一些超参数来调整声谱图的生成方式,但在此之前,我们需要了解如何生成声谱图。
快速傅立叶变换(FFT)
DFT 技术(即分离傅立叶变换)是计算傅立叶变换的一种方法,但 DFT 的计算成本很高,所以实践中通常使用 FFT 算法,这个算法是实现 DFT 的有效方法。
然而,FFT 会把整个时间序列的音频信号作为一个整体来提供频率组件,不会告诉我们这些频率组件在音频信号中是如何随时间变化的。例如,音频第一部分是高频率,而第二部分却是低频率。
短时距傅里叶变换(STFT)
为了得到更精细的视图,并看到频率随时间的变化,我们打算使用 STFT 算法(即短时距傅立叶变换)。STFT 是傅立叶变换的另一种变体,它通过使用滑动时间窗口将音频信号分解成一个个更小的部分,对每个部分进行 FFT,然后再将各个部分合并起来。因此,STFT 算法能够捕捉频率随时间发生的变化。
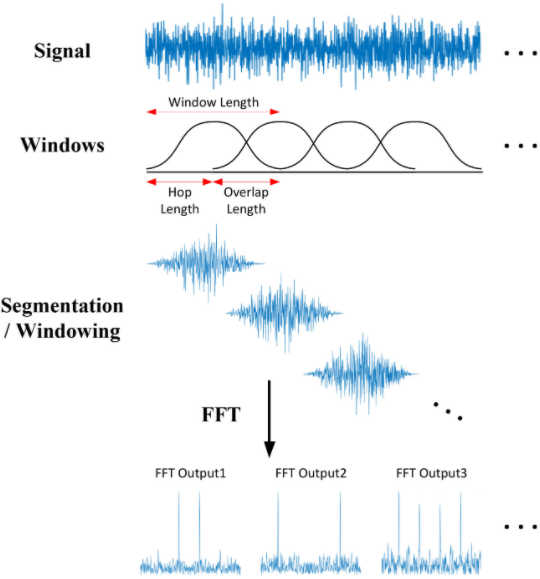
STFT 在音频信号上滑动一个重叠的窗口,并在每个片段上进行傅立叶变换
这样,信号沿时间轴被分成了几部分,而且信号也沿频率轴被分成了几部分,整个频率范围被划分为等距的频带(以梅尔刻度表示)。然后,STFT 可以计算出每个时间段内的频带的振幅或能量。
我们通过下面这个例子来了解。我们有一个 1 分钟的音频片段,其中包含 0 赫兹到 10000 赫兹之间的频率(以梅尔刻度表示)。假设梅尔声谱图的算法为:
-
选择窗口,将音频信号分成 20 个时段。
-
将频率范围划分为 10 个频带(即 0 –1000 赫兹、1000–2000 赫兹、…9000–10000 赫兹)。
该算法的最终输出是形状为(10,20)的 2D Numpy 数组,其中:
-
20 列中的每一列都代表一个时间段的 FFT。
-
10 行中的每行都代表一个频段的振幅值。
我们看第一列,这是第一个时间段的 FFT,有 10 行。
-
第一行是介于 0 –1000 赫兹之间的第一个频段的振幅。
-
第二行是第二个频段在1000 -2000 赫兹之间的振幅。
-
…
数组中的每一列在梅尔声谱图中都变成了“列”。
梅尔声谱图超参数
这是用于调整梅尔声谱图的超参数。我们将使用 Librosa 使用的参数名称。(其他库具有类似参数)
频带
-
fmin——最小频率
-
fmax——显示的最大频率
-
n_mels——频带数(即梅尔滤波器),是声谱图的高度。
时间段
-
n_fft——每个时间段的窗口的长度
-
hop_length——每步滑动窗口所用的样本数。因此,声谱图的宽度=样本总数/ hop_length
你可以根据音频数据类型和要解决的问题来调整这些超参数。
MFCC(用于人类语音)
梅尔声谱图适用于大部分音视频深度学习应用来。但是,对于人类语言(如自动语音识别),MFCC(梅尔频率倒谱系数)的效果有时会更好。
这些本质上是用梅尔声谱图,然后再应用一些进一步处理的步骤。这里有一个人类说话的最常见频率的梅尔声谱图,我们从其中选择了一个压缩的频带表示。
import sklearn
import librosa
import librosa.display
# Load the audio file
samples, sample_rate = librosa.load(AUDIO_FILE, sr=None)
mfcc = librosa.feature.mfcc(samples, sr=sample_rate)
# Center MFCC coefficient dimensions to the mean and unit variance
mfcc = sklearn.preprocessing.scale(mfcc, axis=1)
librosa.display.specshow(mfcc, sr=sample_rate, x_axis='time')
print (f'MFCC is of type {type(mfcc)} with shape {mfcc.shape}')
# MFCC is of type <class 'numpy.ndarray'> with shape (20, 134)
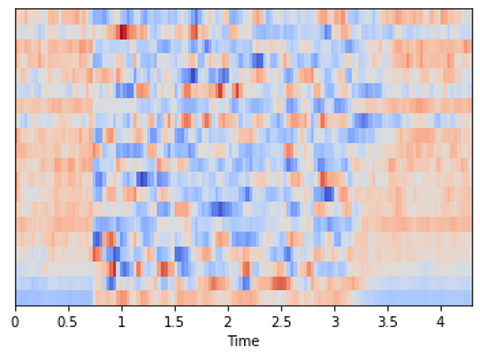
从音频中生成的 MFCC(图像来自作者)
通过以上内容我们发现,相同音频的梅尔声谱图的形状为(128,134),而 MFCC 的形状为(20,134)。MFCC从音频中提取出一组更小的特征,这些特征与捕获声音的基本质量最相关。
数据增强
数据增强是增加数据集多样性的一种常见技术,特别是在没有足够数据时,它可以人工帮你增强数据。我们可以通过对现有数据样本进行小范围的修改来实现这一目的。
拿图像举例,我们可能会对其进行旋转、裁剪、缩放、修改颜色或灯光、或者给图像添加一些噪音。由于图像的语义并没有发生实质性的变化,所以原始样本中的目标标签仍适用于增强样本,例如,如果图像被标记为“猫”,那么增强后的图像也是“猫”。
但是,从模型的角度来看,它就像一个新的数据样本。这有助于把模型泛化到更大范围的图像输入。
和图像数据增强一样,也有增强音频数据的技术,既可以在生成声谱图之前对原始音频进行增强,也可以在已生成的声谱图上进行增强,后者通常效果更好。
声谱图增强
用于图像的普通变换并不适用于声谱图。例如,水平翻转或旋转会改变声谱图和它所代表的声音。
所以,我们使用 SpecAugment 方法来屏蔽声谱图的各个片段。具体如以下两种形式:
-
频率掩码——通过在声谱图上添加水平条来随机屏蔽一系列连续频率。
-
时间掩码——和频率掩码类似,不同之处在于,我们使用竖线在声谱图中随机遮挡时间范围。
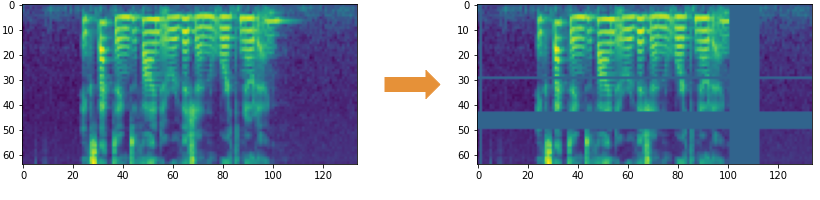
(图片来自作者)
- 原始音频增强
有以下几个选项:
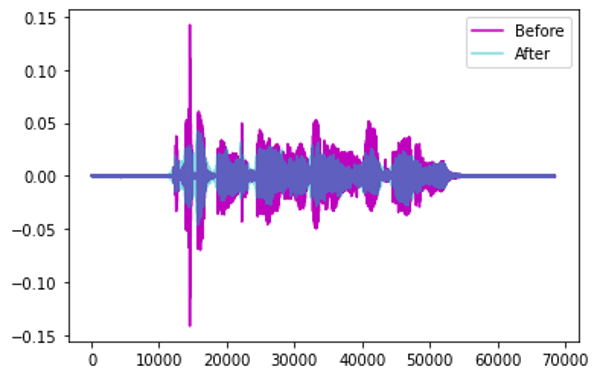
时移——将音频向左或向右随机移动。
- 对于交通或海浪等没有特定顺序的声音,音频可能会环绕。
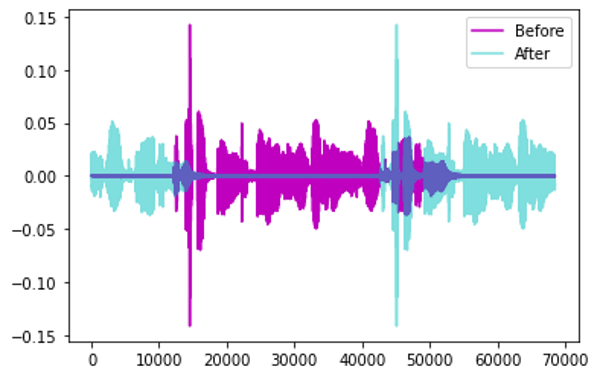
时移增强 (图像来自作者)
- 像人类语音这类很看重顺序的声音,可以用静音来填补间隙。
音调变化——随机修改部分声音的频率。
通过音高移位增强(图像来自作者)
时间拉伸——随机降低或加快声音的速度。
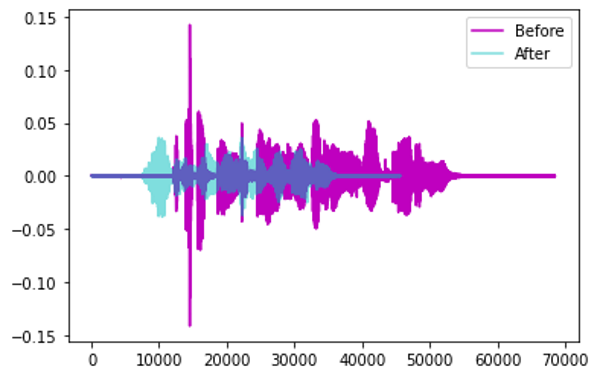
通过时间拉伸进行增强(图像来自作者)
添加噪音——向声音添加一些随机值。
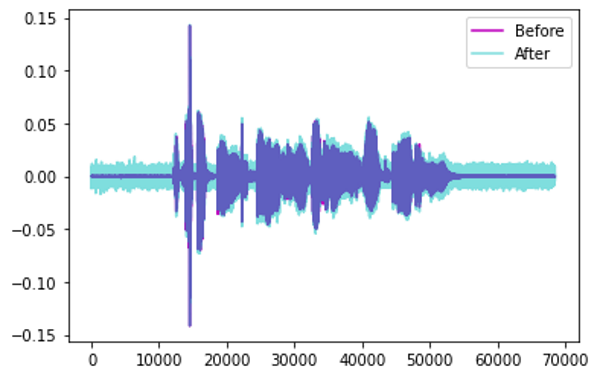
通过添加噪声进行增强(图像来自作者)
结论
我们学习了如何准备和预处理即将输入到深度学习模型的音频数据,上述方法适用于大多数音频应用。
接下来,我们会探索一些深度学习应用。我会在下一篇文章中介绍“音频分类”的示例,一起看这些技术的实际应用。
原文作者 Ketan Doshi
原文链接 https://towardsdatascience.com/audio-deep-learning-made-simple-part-3-data-preparation-and-augmentation-24c6e1f6b52